So apparently my VPS machine isn't up to snuff yet? I'm not sure where the problem is, but it's down for now, so I've removed the redirect (and placed one to here).
If Wil Wheaton can be in exile, so can I, by gum! Maybe it's best to think of this as the "Old World". That makes it sound more enjoyable, huh?
Anyway, it makes a great sort of backup. Sorry about the issues, I'm working on them now.
Extra special thanks to one person who went way above the call of duty in letting me know, and I really appreciate it. I'll post his name if he wants to fess up to it :-)
Friday, July 3, 2009
Welcome to the future!
If you're reading this via RSS reader, I invite you to come visit the new blog! I've got all sorts of enhancements available here, so come check it out!
Lets do an overview of what's new. First, instead of being hosted on blogger's servers, I've got a VPS for the site, and the domain name is www.standalone-sysadmin.com now. Since there are tons of links going to the old site, I've implemented an http meta redirect to a php script that I write. It parses the referrer information and sends the user to the correct page on this site.
The big RSS icon in the top right hand corner of the page links to the feedburner stream. If you subscribe via RSS (and as of today, that's 585 of you out there just at Google Reader), please update your RSS feed to http://feeds.feedburner.com/standalone-sysadmin/rWoU.
The "commentators" box on the right hand side examines user comments, checks the email addresses, and looks them up at Gravatar, the globally recognized avatar database. I've noticed that more and more sites seem to be using it, so if you haven't setup your email over there, maybe you should check into it.
Everything else should be pretty straight forward. I've enabled OpenID logins for those of you who want to use them. The only recurring issue is slowness on the machine. I've talked to the hosting people about that, and when a bigger server opens up, I'll migrate to that. The VPS has 512MB of RAM right now. If this becomes a major problem, I'll temporarily move the blog back to blogger, but I'm hoping that isn't going to be an issue. Let me know if you find it to be.
So that's it. Feel free to leave feedback! Thanks!
Lets do an overview of what's new. First, instead of being hosted on blogger's servers, I've got a VPS for the site, and the domain name is www.standalone-sysadmin.com now. Since there are tons of links going to the old site, I've implemented an http meta redirect to a php script that I write. It parses the referrer information and sends the user to the correct page on this site.
The big RSS icon in the top right hand corner of the page links to the feedburner stream. If you subscribe via RSS (and as of today, that's 585 of you out there just at Google Reader), please update your RSS feed to http://feeds.feedburner.com/standalone-sysadmin/rWoU.
The "commentators" box on the right hand side examines user comments, checks the email addresses, and looks them up at Gravatar, the globally recognized avatar database. I've noticed that more and more sites seem to be using it, so if you haven't setup your email over there, maybe you should check into it.
Everything else should be pretty straight forward. I've enabled OpenID logins for those of you who want to use them. The only recurring issue is slowness on the machine. I've talked to the hosting people about that, and when a bigger server opens up, I'll migrate to that. The VPS has 512MB of RAM right now. If this becomes a major problem, I'll temporarily move the blog back to blogger, but I'm hoping that isn't going to be an issue. Let me know if you find it to be.
So that's it. Feel free to leave feedback! Thanks!
Thursday, July 2, 2009
Update with the hiring and an upcoming blog update
A while back, I talked about hiring another administrator. That process is currently happening and progressing nicely.
If anyone reading the blog applied, thank you. If you didn't receive a call, it is probably because you were far more overqualified than we were looking for. It's a sign of the bad economy that we're having people with 20 years experience applying for junior positions. I hope this turns around for everyone's sake.
Also, even longer ago, I presented a survey which asked an optional open-ended question. What would you do to improve the blog. Well, I hope you're not too attached to how this blog looks right now, because some time over the weekend, it's going to change quite a bit. This new iteration will require you to update the URL for the RSS feed if you're a subscriber.
To facilitate an easier transition, I'm going to be continuing to publish articles here in addition to the new site, so RSS subscribers who haven't caught the news aren't left in the dark. You will automatically be redirected to the new site if you visit this address, though. My plan for it is to be seamless for people visiting, and nearly painless for subscribers. I have no doubt that you'll let me know how it affects you and if something isn't working.
Here's where the fun begins...
If anyone reading the blog applied, thank you. If you didn't receive a call, it is probably because you were far more overqualified than we were looking for. It's a sign of the bad economy that we're having people with 20 years experience applying for junior positions. I hope this turns around for everyone's sake.
Also, even longer ago, I presented a survey which asked an optional open-ended question. What would you do to improve the blog. Well, I hope you're not too attached to how this blog looks right now, because some time over the weekend, it's going to change quite a bit. This new iteration will require you to update the URL for the RSS feed if you're a subscriber.
To facilitate an easier transition, I'm going to be continuing to publish articles here in addition to the new site, so RSS subscribers who haven't caught the news aren't left in the dark. You will automatically be redirected to the new site if you visit this address, though. My plan for it is to be seamless for people visiting, and nearly painless for subscribers. I have no doubt that you'll let me know how it affects you and if something isn't working.
Here's where the fun begins...
Wednesday, July 1, 2009
New Article: Manage Stress Before It Kills You
My newest column is up at Simple Talk Exchange. It's called "Manage Stress Before it Kills You.
It starts out with a true-to-life story of something that happened to me one night. It was scary, but it did let me know that something was wrong. My advice is to manage your stress before it gets to this point, because it isn't an enjoyable experience.
Please make sure to vote up the article if you like it! Thanks!
It starts out with a true-to-life story of something that happened to me one night. It was scary, but it did let me know that something was wrong. My advice is to manage your stress before it gets to this point, because it isn't an enjoyable experience.
Please make sure to vote up the article if you like it! Thanks!
Tuesday, June 30, 2009
Fun with VMware ESXi
Day one of playing with bare metal hypervisors, and I'm already having a blast.
I decided to try ESXi first, since it was the closest relative to what I'm running right now.
Straight out of the box, I run into my first error. I'm installing on a Dell Poweredge 1950 server. The CD boots into an interesting initialization sequence. The screen turns a featureless black, and there are no details as to what is going on behind the scenes. The only indication that the machine isn't frozen is a slowly incrementing progress bar at the bottom. After around 20 minutes (I'm guessing the time it takes to read and decompress an entire installation CD into memory), the screen changes to a menu asking me to hit R if I want to repair, or Enter if I want to install. I want to install, so I hit Enter. Nothing happens, so I hit enter again. And again. And again. It takes a few more times before I realize that the "numlock" light is off. Curious, I hit numlock and it doesn't respond.
Awesome.
I unplug and replug the keyboard in. Nothing. Move it to the front port. Nothing. I reboot and come back to my desk to research. Apparently, I'm not alone. Those accounts are from 2008. I downloaded this CD an hour ago, and it's 3.5 U4 (the most current 3.5x release). It is supposed to have support on the PE1950, but if the keyboard doesn't even work, I have my doubts.
Lots of people have suggested using a PS2 keyboard as the accepted workaround, but in a similar tone to most of my problem/solution options, this server has no PS2 ports.
I'm downloading ESX v4 now. I'll update with how it goes, no doubt.
I decided to try ESXi first, since it was the closest relative to what I'm running right now.
Straight out of the box, I run into my first error. I'm installing on a Dell Poweredge 1950 server. The CD boots into an interesting initialization sequence. The screen turns a featureless black, and there are no details as to what is going on behind the scenes. The only indication that the machine isn't frozen is a slowly incrementing progress bar at the bottom. After around 20 minutes (I'm guessing the time it takes to read and decompress an entire installation CD into memory), the screen changes to a menu asking me to hit R if I want to repair, or Enter if I want to install. I want to install, so I hit Enter. Nothing happens, so I hit enter again. And again. And again. It takes a few more times before I realize that the "numlock" light is off. Curious, I hit numlock and it doesn't respond.
Awesome.
I unplug and replug the keyboard in. Nothing. Move it to the front port. Nothing. I reboot and come back to my desk to research. Apparently, I'm not alone. Those accounts are from 2008. I downloaded this CD an hour ago, and it's 3.5 U4 (the most current 3.5x release). It is supposed to have support on the PE1950, but if the keyboard doesn't even work, I have my doubts.
Lots of people have suggested using a PS2 keyboard as the accepted workaround, but in a similar tone to most of my problem/solution options, this server has no PS2 ports.
I'm downloading ESX v4 now. I'll update with how it goes, no doubt.
Monday, June 29, 2009
Encryption tools for Sysadmins
Every once in a while, someone will ask me what I use for keeping passwords securely. I tell them that I use password safe, which was reccommended to me when *I* asked the question.
Other times, people will ask for simple ways to encrypt or store files. If you're looking for something robust, cross platform, and full featured, you could do a lot worse than TrueCrypt. Essentially, it hooks into the operating system's kernel and allows it to mount entire encrypted volumes as if they were drives. It also has advanced security methods to hide volumes, so that if searched, no volumes would be found without knowing the proper key. In addition, it has a feature that can be valuable if you are seized and placed under duress: in addition to the "real" password, a 2nd can be setup to open another volume, so that your captors believe that you gave them the correct information. Unreal.
So you see that truecrypt is an amazing piece of software. For many things, it's definitely overkill. Instead, you just want something light, that will encrypt a file and that's it. In this case, Gnu Privacy Guard is probably your best bet. I use it in our company to send and receive client files over non secure transfer methods (FTP and the like). With proper Key Exchange, we can be absolutely sure that a file on our servers came from our clients, and vice versa. If you're running a Linux distribution, chances are good you've got GPG installed already. Windows and Mac users will have to get it, but it's absolutely worth it, and the knowledge of how public key encryption works is at the heart of everything from web certificates to ssh authentication. If you want to learn more about how to use it, Simple Help has a tutorial on it, covering the very basic usage. Once you're comfortable with that, check out the manual.
I'm sure I missed some fun ones, so make sure to suggest what you use!
Other times, people will ask for simple ways to encrypt or store files. If you're looking for something robust, cross platform, and full featured, you could do a lot worse than TrueCrypt. Essentially, it hooks into the operating system's kernel and allows it to mount entire encrypted volumes as if they were drives. It also has advanced security methods to hide volumes, so that if searched, no volumes would be found without knowing the proper key. In addition, it has a feature that can be valuable if you are seized and placed under duress: in addition to the "real" password, a 2nd can be setup to open another volume, so that your captors believe that you gave them the correct information. Unreal.
So you see that truecrypt is an amazing piece of software. For many things, it's definitely overkill. Instead, you just want something light, that will encrypt a file and that's it. In this case, Gnu Privacy Guard is probably your best bet. I use it in our company to send and receive client files over non secure transfer methods (FTP and the like). With proper Key Exchange, we can be absolutely sure that a file on our servers came from our clients, and vice versa. If you're running a Linux distribution, chances are good you've got GPG installed already. Windows and Mac users will have to get it, but it's absolutely worth it, and the knowledge of how public key encryption works is at the heart of everything from web certificates to ssh authentication. If you want to learn more about how to use it, Simple Help has a tutorial on it, covering the very basic usage. Once you're comfortable with that, check out the manual.
I'm sure I missed some fun ones, so make sure to suggest what you use!
Thursday, June 25, 2009
Enable Terminal Server on a remote machine
Well, sort of.
This is an old howto that I apparently missed. I really know so little about Windows administration that finding gems like this makes me really excited :-)
Anyway, it's possible to connect to a remote machine's registry, alter the data in it, then remotely reboot the machine so that it can come back up with the server running. That's pretty smooth!
Here are the details.
I know I'm missing tons more stuff like this. What are your favorites?
This is an old howto that I apparently missed. I really know so little about Windows administration that finding gems like this makes me really excited :-)
Anyway, it's possible to connect to a remote machine's registry, alter the data in it, then remotely reboot the machine so that it can come back up with the server running. That's pretty smooth!
Here are the details.
I know I'm missing tons more stuff like this. What are your favorites?
Wednesday, June 24, 2009
Windows Desktop Automated Installations
Over the past couple of weeks, I've had the idea in the back of my mind to build an infrastructure for automated Windows installs, for my users' machines. I've been doing some research (including on ServerFault), and have created a list of software that seems to attempt to fill that niche.
First up is Norton Ghost. From what I can tell, it seems to be the standard image-creating software around. It's been around forever, and according to a slightly skeptical view, seems to be the equivalent of Linux's 'dd' command. It's a piece of commercial software that seems primarily Windows based, but according to the Wiki page supports ext2 and ext3. It does have advanced features, but it looks like you need one license per machine cloned (Experts-Exchange link: scroll to the bottom), and I'm not into spending that sort of money.
Speaking of not spending that sort of money, Acronis True Image has some amazing features. Larger enterprises should probably look into it if they aren't already using it. Just click the link and check the feature set. Nice!
Available for free (sort of) is Microsoft Deployment Services, courtesy of Windows 2008 Server. It's the redesigned version of Remote Installation Services in Server 2003. Word on the street is that it's going to be the recommended way to install Windows 7, winner of the "Most likely to be the next OS on my network when XP is finally unsupported" award. The downside is that I don't currently have any 2008 servers, nor do I plan on upgrading my AD infrastructure. I suppose I could use Remote Installation Services, but eventually I know that I'll upgrade, and then I'll be left learning the new paradigm anyway.
So lets examine some free opensource offerings.
It seems like the most commonly recommended software has been Clonezilla so far. Based on the Diskless Remote Boot in Linux (DRBL), along with half a dozen other free softwares, it seems to support most filesystems capable of being mounted under Linux (including LVM2-hosted filesystems). It comes in two major releases. Clonezilla Live, able to be booted from a CD/DVD/USB drive, and Clonezilla Server Edition, a dedicated image server. If I were going to implement it, I think I'd keep one of each around. They both sound pretty handy for different tasks.
Next up is FOG, the Free Opensource Ghost clone. I haven't come across a ton of documentation for it, but it sounds intriguing. Listening to Clonezilla -vs- FOG peaked my interest, and this is on my list to try. Feel free to drop feedback if you've used it.
Ghost4Linux exists. That's about all I've found. If you know anything about it, and it's good, let me know.
What I've been considering most heavily, Unattended seems very flexible and extensible. It seems to primarily consist of perl scripts, and instead of dealing with images, it automates installs. This has several advantages, mostly that instead of maintaining one image per each model of machine, I can save space by pointing an install to specific drivers necessary for an install, and keep one "base" set of packages.
As soon as I have time, I'm going to start implementing some of these, and I'll write more about them. If you have any experience with this stuff, I'd love to hear from you.
First up is Norton Ghost. From what I can tell, it seems to be the standard image-creating software around. It's been around forever, and according to a slightly skeptical view, seems to be the equivalent of Linux's 'dd' command. It's a piece of commercial software that seems primarily Windows based, but according to the Wiki page supports ext2 and ext3. It does have advanced features, but it looks like you need one license per machine cloned (Experts-Exchange link: scroll to the bottom), and I'm not into spending that sort of money.
Speaking of not spending that sort of money, Acronis True Image has some amazing features. Larger enterprises should probably look into it if they aren't already using it. Just click the link and check the feature set. Nice!
Available for free (sort of) is Microsoft Deployment Services, courtesy of Windows 2008 Server. It's the redesigned version of Remote Installation Services in Server 2003. Word on the street is that it's going to be the recommended way to install Windows 7, winner of the "Most likely to be the next OS on my network when XP is finally unsupported" award. The downside is that I don't currently have any 2008 servers, nor do I plan on upgrading my AD infrastructure. I suppose I could use Remote Installation Services, but eventually I know that I'll upgrade, and then I'll be left learning the new paradigm anyway.
So lets examine some free opensource offerings.
It seems like the most commonly recommended software has been Clonezilla so far. Based on the Diskless Remote Boot in Linux (DRBL), along with half a dozen other free softwares, it seems to support most filesystems capable of being mounted under Linux (including LVM2-hosted filesystems). It comes in two major releases. Clonezilla Live, able to be booted from a CD/DVD/USB drive, and Clonezilla Server Edition, a dedicated image server. If I were going to implement it, I think I'd keep one of each around. They both sound pretty handy for different tasks.
Next up is FOG, the Free Opensource Ghost clone. I haven't come across a ton of documentation for it, but it sounds intriguing. Listening to Clonezilla -vs- FOG peaked my interest, and this is on my list to try. Feel free to drop feedback if you've used it.
Ghost4Linux exists. That's about all I've found. If you know anything about it, and it's good, let me know.
What I've been considering most heavily, Unattended seems very flexible and extensible. It seems to primarily consist of perl scripts, and instead of dealing with images, it automates installs. This has several advantages, mostly that instead of maintaining one image per each model of machine, I can save space by pointing an install to specific drivers necessary for an install, and keep one "base" set of packages.
As soon as I have time, I'm going to start implementing some of these, and I'll write more about them. If you have any experience with this stuff, I'd love to hear from you.
Monday, June 22, 2009
Examine SSL certificate on the command line
This is more for my documentation than anyone elses, but you might find it useful.
To examine an SSL certificate (for use on a secured web server) from the commandline, use this command:
openssl x509 -in filename.crt -noout -text
To examine an SSL certificate (for use on a secured web server) from the commandline, use this command:
openssl x509 -in filename.crt -noout -text
Tuesday, June 16, 2009
More Cable Management
or "I typed a lot on serverfault, I wonder if I can get a blog entry out of it"
Cable management is one of those things that you might be able to read about, but you will never really get the hang of it until you go out and do it. And it takes practice. Good cable management takes a lot of planning, too. You don't get great results if you just throw together a bunch of cable on a rack and call it a day. You've got to plan your runs, order (or create) the right kind of cables and cable management hardware that you need, and it's got to be documented. Only after the documentation is done is the cable job complete (if it even is, then).
When someone asked about Rack Cable Management, I typed out a few of my thoughts, and then kept typing. I've basically pasted it below, because I thought that some of you all might be interested as well.
And just for the record, I've talked about cable management before. Heck, I even did a HOWTO on it a long time ago.
Label each cable
I have a brother P-Touch labeler that I use. Each cable gets a label on both ends. This is because if I unplug something from a switch, I want to know where to plug it back into, and vice versa on the server end.
There are two methods that you can use to label your cables with a generic labeler. You can run the label along the cable, so that it can be read easily, or you can wrap it around the cable so that it meets itself and looks like a tag. The former is easier to read, the latter is either harder to read or uses twice as much label since you type the word twice to make sure it's read. Long labels on mine get the "along the cable" treatment, and shorter ones get the tag.
You can also buy a specific cable labeler which provides plastic sleeves. I've never used it, so I can't offer any advice.
Color code your cables
I run each machine with bonded network cards. This means that I'm using both NICs in each server, and they go to different switches. I have a red switch and a blue switch. All of the eth0's go to red switch using red cables (and the cables are run to the right, and all eth1's go to the blue switch using blue cables (and the cables are run to the left). My network uplink cables are an off color, like yellow, so that they stand out.
In addition, my racks have redundant power. I've got a vertical PDU on each side. The power cables plugged into the right side all have a ring of electrical tape matching the color of the side, again, red for right, blue for left. This makes sure that I don't overload the circuit accidentally if things go to hell in a hurry.
Buy your cables
This may ruffle some feathers. Some people say you should cut cables exactly to length so that there is no excess. I say "I'm not perfect, and some of my crimp jobs may not last as long as molded ends", and I don't want to find out at 3 in the morning some day in the future. So I buy in bulk. When I'm first planning a rack build, I determine where, in relation to the switches, my equipment will be. Then I buy cables in groups based on that distance.
When the time comes for cable management, I work with bundles of cable, grouping them by physical proximity (which also groups them by length, since I planned this out beforehand). I use velcro zip ties to bind the cables together, and also to make larger groups out of smaller bundles. Don't use plastic zip ties on anything that you could see yourself replacing. Even if they re-open, the plastic will eventually wear down and not latch any more.
Keep power cables as far from ethernet cables as possible
Power cables, especially clumps of power cables, cause ElectroMagnetic Interference (EMI aka radio frequency interference (or RFI)) on any surrounding cables, including CAT-* cables (unless they're shielded, but if you're using STP cables in your rack, you're probably doing it wrong). Run your power cables away from the CAT5/6. And if you must bring them close, try to do it at right angles.
Cable management is one of those things that you might be able to read about, but you will never really get the hang of it until you go out and do it. And it takes practice. Good cable management takes a lot of planning, too. You don't get great results if you just throw together a bunch of cable on a rack and call it a day. You've got to plan your runs, order (or create) the right kind of cables and cable management hardware that you need, and it's got to be documented. Only after the documentation is done is the cable job complete (if it even is, then).
When someone asked about Rack Cable Management, I typed out a few of my thoughts, and then kept typing. I've basically pasted it below, because I thought that some of you all might be interested as well.
And just for the record, I've talked about cable management before. Heck, I even did a HOWTO on it a long time ago.
Label each cable
I have a brother P-Touch labeler that I use. Each cable gets a label on both ends. This is because if I unplug something from a switch, I want to know where to plug it back into, and vice versa on the server end.
There are two methods that you can use to label your cables with a generic labeler. You can run the label along the cable, so that it can be read easily, or you can wrap it around the cable so that it meets itself and looks like a tag. The former is easier to read, the latter is either harder to read or uses twice as much label since you type the word twice to make sure it's read. Long labels on mine get the "along the cable" treatment, and shorter ones get the tag.
You can also buy a specific cable labeler which provides plastic sleeves. I've never used it, so I can't offer any advice.
Color code your cables
I run each machine with bonded network cards. This means that I'm using both NICs in each server, and they go to different switches. I have a red switch and a blue switch. All of the eth0's go to red switch using red cables (and the cables are run to the right, and all eth1's go to the blue switch using blue cables (and the cables are run to the left). My network uplink cables are an off color, like yellow, so that they stand out.
In addition, my racks have redundant power. I've got a vertical PDU on each side. The power cables plugged into the right side all have a ring of electrical tape matching the color of the side, again, red for right, blue for left. This makes sure that I don't overload the circuit accidentally if things go to hell in a hurry.
Buy your cables
This may ruffle some feathers. Some people say you should cut cables exactly to length so that there is no excess. I say "I'm not perfect, and some of my crimp jobs may not last as long as molded ends", and I don't want to find out at 3 in the morning some day in the future. So I buy in bulk. When I'm first planning a rack build, I determine where, in relation to the switches, my equipment will be. Then I buy cables in groups based on that distance.
When the time comes for cable management, I work with bundles of cable, grouping them by physical proximity (which also groups them by length, since I planned this out beforehand). I use velcro zip ties to bind the cables together, and also to make larger groups out of smaller bundles. Don't use plastic zip ties on anything that you could see yourself replacing. Even if they re-open, the plastic will eventually wear down and not latch any more.
Keep power cables as far from ethernet cables as possible
Power cables, especially clumps of power cables, cause ElectroMagnetic Interference (EMI aka radio frequency interference (or RFI)) on any surrounding cables, including CAT-* cables (unless they're shielded, but if you're using STP cables in your rack, you're probably doing it wrong). Run your power cables away from the CAT5/6. And if you must bring them close, try to do it at right angles.
Monday, June 15, 2009
The Backup Policy: Databases
It's getting time to revisit my old friend, the backup policy. My boss and I reviewed it last week before he left, and I'm going to spend some time refining the implementation of it.
Essentially, our company, like most, operates on data. The backup policy is designed to ensure that no piece of essential data is lost or unusable, and we try to accomplish that through various backups and archives (read Michael Janke's excellent guest blog entry, "Backups Suck", for more information).
The first thing listed in our backup policy is our Oracle database. It's our primary data store, and at 350GB, a real pain in the butt to transfer around. We've got our primary oracle instance at the primary site (duh?), and it's producing archive logs. That means anytime there's a change in the database, a log file gets written to. We then ship those logs to three machines that are running in "standby mode" where they are replayed to bring the database up to date.
The first standby database is also at the primary site. This enables us to switch over to another database server in an instant if the primary machine crashes with an OS problem or a hardware problem, or something similar that hasn't been corrupting the database for a significant time.
The second standby database is at the backup site. We would move to it in the event that both database machines crash at the primary site (not likely), or if the primary site is rendered unusable for some other reason (slightly more likely). Ideally, we'd have a very fast link (100Mb/s+) between the two sites, but this isn't the case currently, although a link like that is planned in the future.
The third standby database is on the backup server. The backup server is at a 3rd location and has 16-tape library attached to it. In addition to lots of other data that I'll cover in later articles, the Oracle database and historic transaction logs get spooled here so that we can create archives of the database.
These archives would be useful if we found out that several months ago, an unnoticed change went through the database, like a table getting dropped, or some kind of slight corruption that wouldn't bring attention to itself. With archives, we can go back and find out how long it has been that way, or even recover data from before the table was dropped.
Every Sunday, the second standby database is shut down and copied to a test database. After it is copied, it's activated on the test database machine, so that our operations people can test experimental software and data on it.
In addition, a second testing environment is going to be launched at the third site, home of the backup machine. This testing environment will be fed in a similar manner from the third standby database.
Being able to activate these backups help to ensure that our standby databases are a viable recovery mechanism.
The policy states that every Sunday an image will be created from the standby instance. This image will be paired with the archive logs from the next week (Mon-Sat) and written to tape the following Sunday, after which a new image will be created. Two images will be kept live on disk, and another two will be kept in compressed form (It's faster to uncompress a disk than read it from tape).
In the future, I'd like to build in a method to regularly restore a DB image from tape, activate it, and run queries against it, similar to the testing environments. This would extend our "known good" area from the database images to include our backup media.
So that's what I'm doing to prevent data loss from the Oracle DB. I welcome any questions, and I especially welcome any suggestions that would improve the policy. Thanks!
Essentially, our company, like most, operates on data. The backup policy is designed to ensure that no piece of essential data is lost or unusable, and we try to accomplish that through various backups and archives (read Michael Janke's excellent guest blog entry, "Backups Suck", for more information).
The first thing listed in our backup policy is our Oracle database. It's our primary data store, and at 350GB, a real pain in the butt to transfer around. We've got our primary oracle instance at the primary site (duh?), and it's producing archive logs. That means anytime there's a change in the database, a log file gets written to. We then ship those logs to three machines that are running in "standby mode" where they are replayed to bring the database up to date.
The first standby database is also at the primary site. This enables us to switch over to another database server in an instant if the primary machine crashes with an OS problem or a hardware problem, or something similar that hasn't been corrupting the database for a significant time.
The second standby database is at the backup site. We would move to it in the event that both database machines crash at the primary site (not likely), or if the primary site is rendered unusable for some other reason (slightly more likely). Ideally, we'd have a very fast link (100Mb/s+) between the two sites, but this isn't the case currently, although a link like that is planned in the future.
The third standby database is on the backup server. The backup server is at a 3rd location and has 16-tape library attached to it. In addition to lots of other data that I'll cover in later articles, the Oracle database and historic transaction logs get spooled here so that we can create archives of the database.
These archives would be useful if we found out that several months ago, an unnoticed change went through the database, like a table getting dropped, or some kind of slight corruption that wouldn't bring attention to itself. With archives, we can go back and find out how long it has been that way, or even recover data from before the table was dropped.
Every Sunday, the second standby database is shut down and copied to a test database. After it is copied, it's activated on the test database machine, so that our operations people can test experimental software and data on it.
In addition, a second testing environment is going to be launched at the third site, home of the backup machine. This testing environment will be fed in a similar manner from the third standby database.
Being able to activate these backups help to ensure that our standby databases are a viable recovery mechanism.
The policy states that every Sunday an image will be created from the standby instance. This image will be paired with the archive logs from the next week (Mon-Sat) and written to tape the following Sunday, after which a new image will be created. Two images will be kept live on disk, and another two will be kept in compressed form (It's faster to uncompress a disk than read it from tape).
In the future, I'd like to build in a method to regularly restore a DB image from tape, activate it, and run queries against it, similar to the testing environments. This would extend our "known good" area from the database images to include our backup media.
So that's what I'm doing to prevent data loss from the Oracle DB. I welcome any questions, and I especially welcome any suggestions that would improve the policy. Thanks!
Friday, June 12, 2009
Link What is LDAP?
Too busy to really do a big update, but if you've ever wanted to learn what LDAP was, but didn't know who to ask, Sysadmin1138 has a great LDAP WhatIs (that's opposed to a HowTo) on his blog today.
Thursday, June 11, 2009
Today, on a very special Standalone Sysadmin...
I named this blog Standalone Sysadmin for a very good reason. Since 2003 or so, I have very much been a standalone sysadmin. I have worked on networks and infrastructures where, in some cases, the only single point of failure was me. This is not an ideal situation. My bus factor is through the roof.
I have previously complained about the amount of stress that I have at my current position pretty frequently on here (too frequently, really), and I've felt for a long time that it was caused by being the sole point of contact for any IT issues in the organization. The 2008 IT (dis)Satisfaction Survey backed up my beliefs.
After some extended discussions with management about my predicament, they have agreed to help me out by hiring a junior administrator to assist me in keeping the infrastructure together. Horray!
So, here is the job description. We're posting this on Craigslist and Monster. The emphasis is on junior administrator, because of the lack of money we have to put toward the role at the moment. Chances are that if you're already an administrator and you're reading this blog, you are probably more advanced than we're looking for, but maybe you know someone who is smart, young, and wants to get into IT administration, and located somewhere around Berkeley Heights, NJ. It might not be a lot of money, but it's definitely a learning experience, and whoever gets the job will get to play with cool toys ;-)
Here's the original post from Craigslist:
I have previously complained about the amount of stress that I have at my current position pretty frequently on here (too frequently, really), and I've felt for a long time that it was caused by being the sole point of contact for any IT issues in the organization. The 2008 IT (dis)Satisfaction Survey backed up my beliefs.
After some extended discussions with management about my predicament, they have agreed to help me out by hiring a junior administrator to assist me in keeping the infrastructure together. Horray!
So, here is the job description. We're posting this on Craigslist and Monster. The emphasis is on junior administrator, because of the lack of money we have to put toward the role at the moment. Chances are that if you're already an administrator and you're reading this blog, you are probably more advanced than we're looking for, but maybe you know someone who is smart, young, and wants to get into IT administration, and located somewhere around Berkeley Heights, NJ. It might not be a lot of money, but it's definitely a learning experience, and whoever gets the job will get to play with cool toys ;-)
Here's the original post from Craigslist:
Small, growing, and dynamic company is seeking a junior administrator to enhance the sysadmin team. Responsibilities include desktop support, low level server and network administration, and performing on-call rotation with the lead administrator.
The ideal candidate will be an experienced Linux user who has performed some level of enterprise Linux administration (CentOS/RedHat/Slackware preferred). A history of technical support of Windows XP and Mac OS X is valuable, although the amount of remote support is limited. A familiarity with Windows Server 2003 is a plus.
The most important characteristic of our ideal candidate is the ability to learn quickly, think on his/her feet, and adapt to new situations.
Wednesday, June 10, 2009
Opsview->Nagios - Is simpler better?
I'm on the cusp of implementing my new Nagios install at the backup site. It's going to be very similar in terms of configuration to the primary site. At the same time, I'm looking at alternate configuration methods, mostly to see what's out there and available.
Since the actual configuration of Nagios is...labyrinthine, I was looking to see if an effective GUI had been created since the last time I looked. I searched on ServerFault and found that someone had already asked the question for me. The majority of the votes had been thrown toward Opsview, a pretty decent looking interface with lots of the configuration directives available via interface elements. Someone obviously put a lot of work into this, from the screen shots.
It turns out that opsview has a VM image available for testing, so I downloaded it and tried it out. I have to say, the interface is as slick as the screenshots make it out to be. Very smooth experience, with none of the "check the config, find the offending line, fix the typo, check the config..." that editing Nagios configurations by hand tend to produce.
As I was clicking and configuring, I thought back to Michael Janke's excellent post, Ad Hoc -vs- Structured Systems Management (really, go read it. I honestly believe it's his magnum opus). One of the most important lessons is that to maintain the integrity and homogeneity of configuration, you don't click and configure by hand, you use scripts to perform repeatable actions, becayse they're infinitely more accurate than a human clicking and typing.
The ease of access provided by Opsview is tempting, and I can't say that I don't trust it, but I can say that I don't trust myself to click the right boxes all the time. My scripts won't do that. Therefore, I'm going to continue to use my scripts.
Remember, if you can script it, script it. If you can't script it, make a checklist.
Since the actual configuration of Nagios is...labyrinthine, I was looking to see if an effective GUI had been created since the last time I looked. I searched on ServerFault and found that someone had already asked the question for me. The majority of the votes had been thrown toward Opsview, a pretty decent looking interface with lots of the configuration directives available via interface elements. Someone obviously put a lot of work into this, from the screen shots.
It turns out that opsview has a VM image available for testing, so I downloaded it and tried it out. I have to say, the interface is as slick as the screenshots make it out to be. Very smooth experience, with none of the "check the config, find the offending line, fix the typo, check the config..." that editing Nagios configurations by hand tend to produce.
As I was clicking and configuring, I thought back to Michael Janke's excellent post, Ad Hoc -vs- Structured Systems Management (really, go read it. I honestly believe it's his magnum opus). One of the most important lessons is that to maintain the integrity and homogeneity of configuration, you don't click and configure by hand, you use scripts to perform repeatable actions, becayse they're infinitely more accurate than a human clicking and typing.
The ease of access provided by Opsview is tempting, and I can't say that I don't trust it, but I can say that I don't trust myself to click the right boxes all the time. My scripts won't do that. Therefore, I'm going to continue to use my scripts.
Remember, if you can script it, script it. If you can't script it, make a checklist.
Monday, June 8, 2009
Authenticating OpenBSD against Active Directory
I frequent ServerFault when I have spare time, and I found this post excellent today.
It's a step-by-step guide to authenticating OpenBSD against Active Directory.
Great set of instructions, so if you have OpenBSD in a mixed environment, take a look at this.
It's a step-by-step guide to authenticating OpenBSD against Active Directory.
Great set of instructions, so if you have OpenBSD in a mixed environment, take a look at this.
Ah, the pitter patter of new equipment....
Alright, actually really old equipment.
Today my boss is bringing in all of the equipment from the old backup site. There are some fairly heavy duty pieces of equipment, really. I have no idea where I'm going to put it or what I'll do with it all once I get it where it's going, but it's nice to have some spare kit laying around.
Some of it is going to get earmarked for the new tech stuff that I want to learn. Some of the machines have enough processor and RAM that I can make them ESXi hosts, and Hyper-V hosts, since I really do want to try that as well.
There's a 1.6TB external storage array coming on which I'll probably setup Openfiler. It should be fine as a playground for booting VMs over the SAN.
No, the real problem is going to figure out who to cool the machine closet, at this point.
Our building (an 8 floor office building in suburban New Jersey) turns off the air conditioning at 6pm and on the weekends. Normally, this isn't a problem for me, since I've really only got 4 servers and an XRaid here. The additional machines that I'd like to run will cause a significant issue with the ambient temperature, and I'm going to have to figure something out.
I do have a small portable AC unit which I believe will process enough BTUs to take care of it, but I'll have to get the numbers to back that up, and even then I'll have to figure out how to vent it so that I'm not breaking any codes. Definitely have to do research on that.
So there's my next couple of days.
Today my boss is bringing in all of the equipment from the old backup site. There are some fairly heavy duty pieces of equipment, really. I have no idea where I'm going to put it or what I'll do with it all once I get it where it's going, but it's nice to have some spare kit laying around.
Some of it is going to get earmarked for the new tech stuff that I want to learn. Some of the machines have enough processor and RAM that I can make them ESXi hosts, and Hyper-V hosts, since I really do want to try that as well.
There's a 1.6TB external storage array coming on which I'll probably setup Openfiler. It should be fine as a playground for booting VMs over the SAN.
No, the real problem is going to figure out who to cool the machine closet, at this point.
Our building (an 8 floor office building in suburban New Jersey) turns off the air conditioning at 6pm and on the weekends. Normally, this isn't a problem for me, since I've really only got 4 servers and an XRaid here. The additional machines that I'd like to run will cause a significant issue with the ambient temperature, and I'm going to have to figure something out.
I do have a small portable AC unit which I believe will process enough BTUs to take care of it, but I'll have to get the numbers to back that up, and even then I'll have to figure out how to vent it so that I'm not breaking any codes. Definitely have to do research on that.
So there's my next couple of days.
Friday, June 5, 2009
General update and a long weekend ahead
After a week of wrestling with CDW and EMC, two weeks of fighting the storage array, and coming up with an ad hoc environment in something like 2 hours, I've had a rough go of this whole backup-site-activation thing.
The latest wrinkle has been that although EMC shipped us the storage processor, the burned CD with an updated FlareOS was corrupt. You would think, "oh, just download it from the website". At least, that's what I thought. But no. Apparently I'm not special enough to get into that section or something, so I called support, explained the situation, and they told me in their most understanding voice that I had to talk to my sales contact. /sigh
So I called my CDW rep, explained the situation, and he said that he'd get right on it! Excellent. That was, I believe, Tuesday, a bit after the 2nd blog entry. Well, yesterday at 4:30pm he told me that he finally talked to the right people at EMC, and that they'd ship the CD out to me so that I would have it this morning. My reaction might be described as "cautiously optimistic".
Could it be that I finally get to install the 2nd storage processor? Maybe! If I do, it's going to make for a long, long weekend. The EMC docs say that the installation itself takes 6 hours with the software install and reinitialization of the processors. If that last sentence sounds ominous to you, too, it really just means that the software on the controllers gets erased and reinstalled, not the data on the SAN. At least that's what they tell me. I'm going to be extremely unhappy if that's the case.
Tune in next week for the next exciting installment of "How can Matt be screwed by his own ignorance"!
The latest wrinkle has been that although EMC shipped us the storage processor, the burned CD with an updated FlareOS was corrupt. You would think, "oh, just download it from the website". At least, that's what I thought. But no. Apparently I'm not special enough to get into that section or something, so I called support, explained the situation, and they told me in their most understanding voice that I had to talk to my sales contact. /sigh
So I called my CDW rep, explained the situation, and he said that he'd get right on it! Excellent. That was, I believe, Tuesday, a bit after the 2nd blog entry. Well, yesterday at 4:30pm he told me that he finally talked to the right people at EMC, and that they'd ship the CD out to me so that I would have it this morning. My reaction might be described as "cautiously optimistic".
Could it be that I finally get to install the 2nd storage processor? Maybe! If I do, it's going to make for a long, long weekend. The EMC docs say that the installation itself takes 6 hours with the software install and reinitialization of the processors. If that last sentence sounds ominous to you, too, it really just means that the software on the controllers gets erased and reinstalled, not the data on the SAN. At least that's what they tell me. I'm going to be extremely unhappy if that's the case.
Tune in next week for the next exciting installment of "How can Matt be screwed by his own ignorance"!
Thursday, June 4, 2009
I am such a dork
Yes, that was my real reputation score when I logged into serverfault.com this evening. The masses agree :-)
Future Tech I want to try out
In the near future, I may be allowed to have a little more quality time with my infrastructure, so when that happens, I want to be able to hit the ground running. To that end, I wanted to enumerate some of the technologies I want to be trying, since I know lots of you really like cool projects.
How about you? If you had the time, what would you want to spend some time learning?
- Desktop/Laptop Management
- DRBD
- Puppet
- ZFS
- OpenSolaris
I want to work on centrally managing my users' machines. I already mentioned rolling out machine upgrades in flights. That way all I can distribute all machines pre-configured, domain authenticated, really take advantage of some microsoft-y technologies like Group Policy object to install any additional software on the fly. I want to do network-mapped home directories, as well, which I can only do on those users who have machines which have been added to the domain. I'd also like a little more full-featured computer management solution. I'm really sort of leaning towards (at least) trying Admin Arsenal, who did a guest blog spot last week. I'll have to do some more evaluating and try some test runs to see how it goes.
DRBD just sounds like a cool technology. Essentially you create a clustered filesystem, even though both machines aren't connected by anything other than a network. The scheme is called "shared nothing", and from what I have read, the filesystem is synced on a block level over the network. I can definitely see how it would be valuable, but I have lots of questions about what happens during network outages and the like. Ideally I would be able to setup a lab and go at it.
Puppet was the darling of the configuration management world for a long time. According to the webpage, it translates IT policy into configurations. It sounds like alchemy, but I'm willing to give it a shot, since so many people recommend it so highly. Speaking of people recommending something highly....
Somewhere on the hierarchy of great things, this is reputedly somewhere between sliced bread and..well, pretty much whatever is better than ZFS. That's a long list, no doubt, but reports are fuzzy on where bacon stands on the scale. In any event, if you've recently asked a Solaris user what filesystem is best for...pretty much anything, chances are good that they've recommended ZFS. If you've offered any resistance at all, you've probably heard echoes of "But....snapshots! Copy on write! 16 exibytes!". I suspect that its allure would probably lessen if it were actually available on Linux instead of being implemented in FUSE, but that's probably sour grapes. And in order to actually try it, I'm going to need to try...
All the fun of old school Unix without any of the crappy gnu software making us soft and weak. OpenSolaris became available when Sun released the source to Solaris, and a community sprung up around it. Learning (Open)Solaris is actually pretty handy since it runs some pretty large scale hardware and apparently there's some really nice filesystem for it or something that everyone is talking about. I don't know, but I'd like to give it a shot.
How about you? If you had the time, what would you want to spend some time learning?
Wednesday, June 3, 2009
Switching from piecemeal machines to leases
I've got a small number of users for the number of servers I manage. Right now, there's around 15 users in the company, and nearly all of them have laptops. We currently run an astonishing array of different models, each bought sometime in the previous four years. Because of this, no two are alike, and support is a nightmare.
I want to switch from the process we have in place now to a lease based plan, where my users are upgraded in "flights", so to speak. The benefits will be tremendous. I'll be able to roll out a standard image instead of wondering who has what version of what software, issues will be much easier to debug, and I can conduct thorough tests before rollout.
My problem is that I've never done leases nor planned rollouts like this. What advice would you give to someone who is just doing this for the first time?
See the related question on serverfault, as well!
I want to switch from the process we have in place now to a lease based plan, where my users are upgraded in "flights", so to speak. The benefits will be tremendous. I'll be able to roll out a standard image instead of wondering who has what version of what software, issues will be much easier to debug, and I can conduct thorough tests before rollout.
My problem is that I've never done leases nor planned rollouts like this. What advice would you give to someone who is just doing this for the first time?
See the related question on serverfault, as well!
Tuesday, June 2, 2009
Update: The storage gods heard my lament
and delivered my extra storage processor! Praise be to EMC. Or something like that.
Now to figure out where in the rack to jam the batteries ;-)
Now to figure out where in the rack to jam the batteries ;-)
The god of storage hates me, I know it
It seems like storage and I never get along. There's always some difficulty somewhere. It's always that I don't have enough, or I don't have enough where I need it, and there's always the occasional sorry-we-sold-you-a-single-controller followed by I'll-overnight-you-another-one which appears to be concluded by sorry-it-won't-be-there-until-next-week. /sigh
So yes, looking back at my blog's RSS feed, it was Wednesday of last week that I discovered the problem was the lack of a 2nd storage controller, and it was that same day that we ordered another controller. We asked for it to be overnighted. Apparently overnight is 6 days later, because it should come today. I mean, theoretically, it might not, but hey, I'm an optimist. Really.
Assuming that it does come today, I'm driving to Philadelphia to install it into the chassis. If it doesn't come, I'm driving to Philadelphia to install another server into the rack, because we promised operations that they'd have a working environment by Wednesday, then I'm going again whenever the part comes.
In almost-offtopic news, I am quickly becoming a proponent of the "skip a rack unit between equipment" school of rack management. You see, there are people like me who shove all of the equipment together so that they can maintain a chunk of extra free space in the rack in case something big comes along. Then there are people who say that airflow and heat dissipation are no good when the servers are like that, so they leave one rack unit between their equipment.
I've got blades, so skipping a RU wouldn't do much for my heat dissipation, but my 2nd processor kit is coming with a 1u pair of battery backups for the storage array and I REALLY wish that I hadn't put the array on the bottom of the rack and left the nearest free space about 15 units above it. I'm going to have to do some rearranging, and I'm not sure what I can move yet.
So yes, looking back at my blog's RSS feed, it was Wednesday of last week that I discovered the problem was the lack of a 2nd storage controller, and it was that same day that we ordered another controller. We asked for it to be overnighted. Apparently overnight is 6 days later, because it should come today. I mean, theoretically, it might not, but hey, I'm an optimist. Really.
Assuming that it does come today, I'm driving to Philadelphia to install it into the chassis. If it doesn't come, I'm driving to Philadelphia to install another server into the rack, because we promised operations that they'd have a working environment by Wednesday, then I'm going again whenever the part comes.
In almost-offtopic news, I am quickly becoming a proponent of the "skip a rack unit between equipment" school of rack management. You see, there are people like me who shove all of the equipment together so that they can maintain a chunk of extra free space in the rack in case something big comes along. Then there are people who say that airflow and heat dissipation are no good when the servers are like that, so they leave one rack unit between their equipment.
I've got blades, so skipping a RU wouldn't do much for my heat dissipation, but my 2nd processor kit is coming with a 1u pair of battery backups for the storage array and I REALLY wish that I hadn't put the array on the bottom of the rack and left the nearest free space about 15 units above it. I'm going to have to do some rearranging, and I'm not sure what I can move yet.
Friday, May 29, 2009
Outstanding new sysadmin resource
I always like posting cool sites and resources that I find, and man, today's is no exception.
I'm willing to bet a bunch of you have already heard of it and are probably participating. It just got out of beta the other day, and it's live for new members. It's called Server Fault, created by the same people who did Stack Overflow.
The general idea is that a sysadmin asks a question to the group. People answer the question in the thread, and the question (and answers) get voted up and down. Think of it like Reddit with a signal to noise ratio of infinity.
I've been active on there, checking it out, and while it's frustrating in the beginning (you can't do anything but ask and answer questions, and in your answers you can't even include links. As your questions and answers get voted up, you receive "reputation", and as your reputation improves, you get more abilities on the site. Like an RPG or something, I guess. Check the FAQ for more details.
The absolute best part is that you can learn more and more and more, all the time. I can't tell you how many questions I've seen where I thought "I've always sort of wondered that, too", and I just never took the time to research it. *click*
It's outstanding, and as a technical resource, probably unparalleled in the sysadmin world. Let me know what you think of it (and post a link to your account, if you'd like. Mine is here).
I'm willing to bet a bunch of you have already heard of it and are probably participating. It just got out of beta the other day, and it's live for new members. It's called Server Fault, created by the same people who did Stack Overflow.
The general idea is that a sysadmin asks a question to the group. People answer the question in the thread, and the question (and answers) get voted up and down. Think of it like Reddit with a signal to noise ratio of infinity.
I've been active on there, checking it out, and while it's frustrating in the beginning (you can't do anything but ask and answer questions, and in your answers you can't even include links. As your questions and answers get voted up, you receive "reputation", and as your reputation improves, you get more abilities on the site. Like an RPG or something, I guess. Check the FAQ for more details.
The absolute best part is that you can learn more and more and more, all the time. I can't tell you how many questions I've seen where I thought "I've always sort of wondered that, too", and I just never took the time to research it. *click*
It's outstanding, and as a technical resource, probably unparalleled in the sysadmin world. Let me know what you think of it (and post a link to your account, if you'd like. Mine is here).
Thursday, May 28, 2009
Software Deployment in Windows, courtesy of Admin Arsenal
One of the blogs that I read frequently is Admin Arsenal. To be honest, they're really the only commercial/corporate blog that I follow, because it's about many aspects of Windows administration, and doesn't just focus on their product.
Shawn Anderson, one of the guys who works there (and a frequent reader here on Standalone Sysadmin), took me up on my offer of hosting guest blog spots, and asked if I would host something written by the Admin Arsenal staff. I agreed, under the condition that the entry wasn't a commercial disguised as a blog entry. Of course their product is mentioned in this entry, but I don't feel that it is over the top or out of place.
The topic we discussed was remote software installation on Windows, something that has always seemed like black magic to me, someone who has no Windows background, and I figured it would be something that many of you would be interested in as well.
In the interest of full disclosure, I should say that I am not getting paid or reimbursed in any way for this blog entry. If you feel that allowing companies (even companies with blogs that I enjoy) submit guest blogs, say so in the comments. In the end, this is ultimately my blog, but I'm not so stubborn as to not listen to wise counsel.
Let me just reiterate here that anyone who has a topic of interest and wants to do a guest blog is welcome to drop me a line. The chances are great that I'll be very happy to host your work, and that many people would love to read it.
Without further ado, here's the guest entry from Admin Arsenal!
Ren McCormack says that Ecclesiastes assures us that "there is a time for every purpose under heaven. A time to laugh (upgrading to Windows 7), a time to weep (working with Vista), a time to mourn (saying goodbye to XP) and there is a time to dance." If you haven't seen Footloose then you have a homework assignment. Go rent it. Now.
OK, 80's movie nostalgia aside, let's talk about the "dance". Deployment. Almost every system admin knows the pain of having to deploy software to dozens or hundreds or even thousands of systems. Purchasing deployment tools can get very pricey and learning how to use the new tools can be overwhelming especially if you are new to the world of Software Deployment. Here are a few tips to help you in your Software Deployment needs.
Group Policy
Deploying software via Group Policy is relatively easy and has some serious benefits. If you have software that needs to "follow" a user then Group Policy is the way to go. As particular users move from computer to computer you can be certain that the individual software needed is automatically installed when the user logs on. A downside to this approach is that any application you wish to install via Group Policy really needs to be in the form of a Windows Installer package (MSI, MSP, MSU, etc). You can still deploy non-Windows Installer applications but you need to create a ZAP file and you lose most of the functionality (such as having the software follow a user). It's also difficult to get that quick installation performed and verified. Generally speaking, you're going to wait a little while for your deployment to complete.
SMS / SCCM
If you are a licensed user of SMS / SCCM then you get the excellent SMS Installer application. SMS Installer is basically version 5 of the old Wise Installer. With SMS Installer you can create custom packages or combine multiple applications into one deployment. You can take a "before" snapshot of your computer, install an application, customize that application and then take an "after" snapshot. The changes that comprise the application are detected and the necessary files, registry modifications, INI changes etc are "packaged" up into a nice EXE. Using this method you ultimately have excellent control over how applications are installed. A key strength to using the SMS Installer is found when you need to deploy software that does not offer "Silent" or "Quiet" installations.
A downside to using SMS is the cost and complexity. Site servers. Distribution Point servers. Advertisement creation... it's a whole production.
Admin Arsenal
Admin Arsenal provides a quick and easy way to deploy software. Once you provide the installation media and the appropriate command line arguments the deployment is ready to begin. The strength is the ease and speed of deployment. No extra servers are needed. No need to repackage existing installations. A downside to Admin Arsenal is that it if the application you want to deploy does not have the ability to run in silent or quiet mode (this limitation is occasionally found in freeware or shareware) then you need to take a few extra steps to deploy.
Most applications now-a-days allow for silent or quiet installations. If your deployment file ends in .MSI, .MSU or .MSP then you know the silent option is available. Most files that end in .EXE allow for a silent installation.
Refer to Adam's excellent blog entry called the 5 Commandments of Software Deployment.
Disclaimer: I currently work for Admin Arsenal, so my objectivity can and should be taken into consideration. There are many solutions commercially available for deploying software. Take a dip in the pool. Find what works for you. If the software has a trial period, put it to the test. There are solutions for just about every need and budget. Feel free to shoot questions to me about your needs or current deployment headaches.
Shawn Anderson, one of the guys who works there (and a frequent reader here on Standalone Sysadmin), took me up on my offer of hosting guest blog spots, and asked if I would host something written by the Admin Arsenal staff. I agreed, under the condition that the entry wasn't a commercial disguised as a blog entry. Of course their product is mentioned in this entry, but I don't feel that it is over the top or out of place.
The topic we discussed was remote software installation on Windows, something that has always seemed like black magic to me, someone who has no Windows background, and I figured it would be something that many of you would be interested in as well.
In the interest of full disclosure, I should say that I am not getting paid or reimbursed in any way for this blog entry. If you feel that allowing companies (even companies with blogs that I enjoy) submit guest blogs, say so in the comments. In the end, this is ultimately my blog, but I'm not so stubborn as to not listen to wise counsel.
Let me just reiterate here that anyone who has a topic of interest and wants to do a guest blog is welcome to drop me a line. The chances are great that I'll be very happy to host your work, and that many people would love to read it.
Without further ado, here's the guest entry from Admin Arsenal!
 |
Ren McCormack says that Ecclesiastes assures us that "there is a time for every purpose under heaven. A time to laugh (upgrading to Windows 7), a time to weep (working with Vista), a time to mourn (saying goodbye to XP) and there is a time to dance." If you haven't seen Footloose then you have a homework assignment. Go rent it. Now.
OK, 80's movie nostalgia aside, let's talk about the "dance". Deployment. Almost every system admin knows the pain of having to deploy software to dozens or hundreds or even thousands of systems. Purchasing deployment tools can get very pricey and learning how to use the new tools can be overwhelming especially if you are new to the world of Software Deployment. Here are a few tips to help you in your Software Deployment needs.
Group Policy
Deploying software via Group Policy is relatively easy and has some serious benefits. If you have software that needs to "follow" a user then Group Policy is the way to go. As particular users move from computer to computer you can be certain that the individual software needed is automatically installed when the user logs on. A downside to this approach is that any application you wish to install via Group Policy really needs to be in the form of a Windows Installer package (MSI, MSP, MSU, etc). You can still deploy non-Windows Installer applications but you need to create a ZAP file and you lose most of the functionality (such as having the software follow a user). It's also difficult to get that quick installation performed and verified. Generally speaking, you're going to wait a little while for your deployment to complete.
SMS / SCCM
If you are a licensed user of SMS / SCCM then you get the excellent SMS Installer application. SMS Installer is basically version 5 of the old Wise Installer. With SMS Installer you can create custom packages or combine multiple applications into one deployment. You can take a "before" snapshot of your computer, install an application, customize that application and then take an "after" snapshot. The changes that comprise the application are detected and the necessary files, registry modifications, INI changes etc are "packaged" up into a nice EXE. Using this method you ultimately have excellent control over how applications are installed. A key strength to using the SMS Installer is found when you need to deploy software that does not offer "Silent" or "Quiet" installations.
A downside to using SMS is the cost and complexity. Site servers. Distribution Point servers. Advertisement creation... it's a whole production.
Admin Arsenal
Admin Arsenal provides a quick and easy way to deploy software. Once you provide the installation media and the appropriate command line arguments the deployment is ready to begin. The strength is the ease and speed of deployment. No extra servers are needed. No need to repackage existing installations. A downside to Admin Arsenal is that it if the application you want to deploy does not have the ability to run in silent or quiet mode (this limitation is occasionally found in freeware or shareware) then you need to take a few extra steps to deploy.
Most applications now-a-days allow for silent or quiet installations. If your deployment file ends in .MSI, .MSU or .MSP then you know the silent option is available. Most files that end in .EXE allow for a silent installation.
Refer to Adam's excellent blog entry called the 5 Commandments of Software Deployment.
Disclaimer: I currently work for Admin Arsenal, so my objectivity can and should be taken into consideration. There are many solutions commercially available for deploying software. Take a dip in the pool. Find what works for you. If the software has a trial period, put it to the test. There are solutions for just about every need and budget. Feel free to shoot questions to me about your needs or current deployment headaches.
Wednesday, May 27, 2009
Followup to slow SAN speed
I mentioned this morning that I was having slow SAN performance. I said that I'd post an update if I figured out what was wrong, and I did.
EMC AX4-5's with a single processor have a known issue, apparently. Since there's only one storage controller on the unit, it intentionally disables write cache. Oops. I didn't even have to troubleshoot with the engineer. It was pretty much "Do you only have one processor in this?" "yes" "Oh, well, there's your problem right there".
So yea, if you're thinking about an EMC AX4-5, make sure to pony up the extra cash...err..cache..err..whatever.
EMC AX4-5's with a single processor have a known issue, apparently. Since there's only one storage controller on the unit, it intentionally disables write cache. Oops. I didn't even have to troubleshoot with the engineer. It was pretty much "Do you only have one processor in this?" "yes" "Oh, well, there's your problem right there".
So yea, if you're thinking about an EMC AX4-5, make sure to pony up the extra cash...err..cache..err..whatever.
SAN performance issues with the new install
So, you would think that 12 spindles would be...you know...fast.
Even if you took 12 spindles, made them into a RAID 10 array, they'd still be fast.
That's what I'd think, anyway. It turns out, my new EMC AX4 is having a bit of a problem. None of the machines hooked to it can reach > 30MB/s (which is 240Mb/s in bandwidth-talk). I haven't been able to determine the bottleneck yet, either.
I've discounted the switch. The equipment is nearly identical to that in the existing primary site (using SATA in the backup rather than SAS, but still, 30MB?). It isn't the cables. Port speeds read correctly (4GB from the storage array, 2GB from the servers).
The main difference is that the storage unit only has one processor, but I can't bring myself to believe that one processor can't push/pull over 30MB/s. I originally had it arranged as RAID 6, and I thought that maybe the two checksum computations were too much for it, but now with RAID 10, I'm seeing the same speed, so I don't think the processor is the bottleneck.
I'm just plain confused. This morning I'm going to be calling EMC. I've got a case open with their tech support, so hopefully I'll be able to get to the bottom of it. If it's something general, I'll make sure to write about it. If it's the lack of a 2nd storage processor, I'll make sure to complain about it. Either way, fun.
Even if you took 12 spindles, made them into a RAID 10 array, they'd still be fast.
That's what I'd think, anyway. It turns out, my new EMC AX4 is having a bit of a problem. None of the machines hooked to it can reach > 30MB/s (which is 240Mb/s in bandwidth-talk). I haven't been able to determine the bottleneck yet, either.
I've discounted the switch. The equipment is nearly identical to that in the existing primary site (using SATA in the backup rather than SAS, but still, 30MB?). It isn't the cables. Port speeds read correctly (4GB from the storage array, 2GB from the servers).
The main difference is that the storage unit only has one processor, but I can't bring myself to believe that one processor can't push/pull over 30MB/s. I originally had it arranged as RAID 6, and I thought that maybe the two checksum computations were too much for it, but now with RAID 10, I'm seeing the same speed, so I don't think the processor is the bottleneck.
I'm just plain confused. This morning I'm going to be calling EMC. I've got a case open with their tech support, so hopefully I'll be able to get to the bottom of it. If it's something general, I'll make sure to write about it. If it's the lack of a 2nd storage processor, I'll make sure to complain about it. Either way, fun.
Tuesday, May 26, 2009
Monitor Dell Warranty
A post over at Everything Sysadmin pointed me to an excellent Nagios plugin: Monitor Dell Warranty Expiration. Great idea!
That was a well needed break
As of last Wednesday, I had gone 31 days with only one day off in the preceding month. I was burned out. Fortunately, this coincided with my friends coming to visit my wife and I from Ohio, so this gave me an excellent opportunity to deman^H^H^H^H^Hrequest time off, and they gave it to me.
For the past 5 days or so, I've been off and running around the NY/NJ area, doing all sorts of touristy things with our friends, and just exploring NYC like I haven't had the chance to before. We spent an entire day at the American Museum of Natural History, and I finally got to go to the Hayden Planetarium to see Cosmic Collisions. It was absolutely worth it, and I'm so glad I picked up a membership on my first visit.
I finally got to go visit Liberty Island and see the statue. It was great, very impressive. After July 4th, they're going to be opening up the crown, but until then, you can only go to the top of the pedestal. It was still a great view.
Ate lots of great food, had a good time with my friends, and today I'm back at work. We're switching over to a new backup site this week. Hopefully things will go smoother than they have the week prior to my vacation, but we'll see, and I'll write about it.
So did I miss anything good?
For the past 5 days or so, I've been off and running around the NY/NJ area, doing all sorts of touristy things with our friends, and just exploring NYC like I haven't had the chance to before. We spent an entire day at the American Museum of Natural History, and I finally got to go to the Hayden Planetarium to see Cosmic Collisions. It was absolutely worth it, and I'm so glad I picked up a membership on my first visit.
I finally got to go visit Liberty Island and see the statue. It was great, very impressive. After July 4th, they're going to be opening up the crown, but until then, you can only go to the top of the pedestal. It was still a great view.
Ate lots of great food, had a good time with my friends, and today I'm back at work. We're switching over to a new backup site this week. Hopefully things will go smoother than they have the week prior to my vacation, but we'll see, and I'll write about it.
So did I miss anything good?
Friday, May 15, 2009
Security is a process and not plug&play
I got a SANS pamphlet in the mail today, which makes me feel guilty. Not really guilty, as in "I should go but I'm not" (even though I should, and I'm not), but because in terms of IT security, I've sort of been in the "Oh, I'm sure that'll be fine while I'm doing all of this other stuff" mode. It's not a good practice to be in, but I don't see any way to give IT security the attention it deserves when all (and I mean all) of my free time is spent building new infrastructure and stopping the existing infrastructure from falling apart. And if you don't believe me,
msimmons@newcastle:~$ ps aux | grep Eterm | wc -l
21
That's not counting the VMs that are installing right now, or the VM diagram I'm using to keep track of which physical machine will be getting what virtual machine.
I cringe whenever I think about this phrase, but I don't have enough time to worry about security. The automatic response to that (even from/to myself) is "do you have enough time to clean up a break in?". I'm not monitoring logs like I want, and I don't even have enough time to set up a log monitoring system to do it for me. I'm hoping that in a few weeks things will relax and I can start putting emphasis where it should be, but it isn't right now. I really need more staff to give proper types of attention to security, various Oracle, Postgres, and MySQL databases, site buildouts, asset management, user support, and backups, but I don't have it, so I find myself juggling all of those various tasks, and my stress level is directly related to how many balls are in the air at one time.
Looking through the SANS booklet, I see all kinds of classes that I'd love to take (the Network PenTest / Ethical Hacking class, for one) but I can't even foresee enough free time to take the class, let alone utilize it.
Have any of you ever been to a SANS conference and received training? Was it worth it? How did you get to use it back at your job? Cheer me up and regale me with stories of success from conference training ;-)
msimmons@newcastle:~$ ps aux | grep Eterm | wc -l
21
That's not counting the VMs that are installing right now, or the VM diagram I'm using to keep track of which physical machine will be getting what virtual machine.
I cringe whenever I think about this phrase, but I don't have enough time to worry about security. The automatic response to that (even from/to myself) is "do you have enough time to clean up a break in?". I'm not monitoring logs like I want, and I don't even have enough time to set up a log monitoring system to do it for me. I'm hoping that in a few weeks things will relax and I can start putting emphasis where it should be, but it isn't right now. I really need more staff to give proper types of attention to security, various Oracle, Postgres, and MySQL databases, site buildouts, asset management, user support, and backups, but I don't have it, so I find myself juggling all of those various tasks, and my stress level is directly related to how many balls are in the air at one time.
Looking through the SANS booklet, I see all kinds of classes that I'd love to take (the Network PenTest / Ethical Hacking class, for one) but I can't even foresee enough free time to take the class, let alone utilize it.
Have any of you ever been to a SANS conference and received training? Was it worth it? How did you get to use it back at your job? Cheer me up and regale me with stories of success from conference training ;-)
Thursday, May 14, 2009
Happy 1st Blogiversary!
I'm very, very happy to announce that today is Standalone Sysadmin's first Blogiversary! That's right, last year at this time, I posted my Introduction and Welcome. Little did I know that less than a year later, this blog would have over 500 subscribers, have hit the Slashdot front page, and gained a loyal following of the best readers a blogger could ever ask for.
Thank you all so much. It wouldn't be possible, or even worth doing, if people out there didn't visit, read, and write comments, emails, and twitter back. You all rock.
So since it's a celebration of sorts today, let us not go without presents!
A while back (ok, like 6 months ago), I created a survey that I called the 2008 IT Admin Job (dis)Satisfaction Survey. Over the course of two weeks, 334 of you took that survey to let other people know what it was like to be you. It was an amazing amount of information. Even as the results were still coming in, I could tell that there was a lot of pent up frustration. I would have liked to have compiled the results before now, but the amount of information was so massive, and I have no experience with anything like this, that I didn't know how to approach it.
I believe I've finally got a handle on a roughly usable format. I've created an overview of the survey (.doc format) with comments from me, and because I firmly believe in the open sharing of information, I am providing a raw CSV file of the responses (with identifying information strippped) so that you can go do crazy things with the data and come up with new interesting combinations on your own. Knock yourselves out, but if you find something interesting, make sure to drop me a line, and if you publish your own findings, just point a link back to this site, if you would. (Many thanks to NoNeck for hosting these files!)
In a slightly different twist, I don't know if you've heard, but the Amazon Kindle store has been promising to make blogs available via subscription for a while, and I signed up for information a while back, and just got it today.
The short story is that you can now subscribe to Standalone Sysadmin on your Kindle. The price is currently set at $2/month, not because I particularly think that anyone will pay that (or even that it's worth that) but I haven't figured out how to lower the price yet :-)
In the meantime, if you have a kindle and you absolutely MUST read my updates, feel free to subscribe, I get something like 30% of the cost. I won't be insulted if you pass, and I'll update whenever I figure out how to lower the price.
So that's that. Year 1 in the bag, with hopefully many more to come. Thanks again everyone, I can't tell you how much I appreciate each and every one of you who comes here. Thank you and take care.
--Matt
Thank you all so much. It wouldn't be possible, or even worth doing, if people out there didn't visit, read, and write comments, emails, and twitter back. You all rock.
So since it's a celebration of sorts today, let us not go without presents!
A while back (ok, like 6 months ago), I created a survey that I called the 2008 IT Admin Job (dis)Satisfaction Survey. Over the course of two weeks, 334 of you took that survey to let other people know what it was like to be you. It was an amazing amount of information. Even as the results were still coming in, I could tell that there was a lot of pent up frustration. I would have liked to have compiled the results before now, but the amount of information was so massive, and I have no experience with anything like this, that I didn't know how to approach it.
I believe I've finally got a handle on a roughly usable format. I've created an overview of the survey (.doc format) with comments from me, and because I firmly believe in the open sharing of information, I am providing a raw CSV file of the responses (with identifying information strippped) so that you can go do crazy things with the data and come up with new interesting combinations on your own. Knock yourselves out, but if you find something interesting, make sure to drop me a line, and if you publish your own findings, just point a link back to this site, if you would. (Many thanks to NoNeck for hosting these files!)
In a slightly different twist, I don't know if you've heard, but the Amazon Kindle store has been promising to make blogs available via subscription for a while, and I signed up for information a while back, and just got it today.
The short story is that you can now subscribe to Standalone Sysadmin on your Kindle. The price is currently set at $2/month, not because I particularly think that anyone will pay that (or even that it's worth that) but I haven't figured out how to lower the price yet :-)
In the meantime, if you have a kindle and you absolutely MUST read my updates, feel free to subscribe, I get something like 30% of the cost. I won't be insulted if you pass, and I'll update whenever I figure out how to lower the price.
So that's that. Year 1 in the bag, with hopefully many more to come. Thanks again everyone, I can't tell you how much I appreciate each and every one of you who comes here. Thank you and take care.
--Matt
Saturday, May 9, 2009
Obtaining the WWPN of fibre channel HBAs
Last week, I installed all of the equipment in our beta site. Due to issues with the power at my office, I wasn't able to touch the blades for the month or so before they went in the rack, and the last time they were powered on, I didn't have the storage array to make sure that they could talk. Now I'm in the position of needing to match up which connected HBAs go to which machines.
Researching, I found this entry on a blog called "sysdigg". Sysdigg looks like an interesting blog until you go to the current site, where it's mostly spam and ads. I'm not sure what happened, but at least back in 2007 it looked informative.
Anyway, the key lies in having a modern kernel and sysfs. There's a class called fc_host with the appropriate info:
> cat /sys/class/fc_host/host*/port_name
This is more documentation for myself, since I always forget, but maybe it will help someone else too.
Friday, May 8, 2009
Quick blurb: Nagios is forked
Jack Hughes over at The Tech Teapot posted today that Nagios has been forked. Apparently the lead developer (and sole person with commit access) has been very busy and not committing updates. This caused some self-described protagonists to launch "Icinga".
It's going to be very interesting to see where this goes. I personally hope that Nagios itself picks back up. My Nagios 3 installation is great, and I love it. I've had nothing but good things to say about it. If it doesn't pick back up, I have to wonder how many people will just move to OpenNMS.
It's going to be very interesting to see where this goes. I personally hope that Nagios itself picks back up. My Nagios 3 installation is great, and I love it. I've had nothing but good things to say about it. If it doesn't pick back up, I have to wonder how many people will just move to OpenNMS.
Thursday, May 7, 2009
NVidia's Tesla C1060 - The FM principle?
 I've been hearing a lot about NVidia's new "super computer on your desk", but all I can really find is marketing talk. I was skeptical of the claims until I went to the site and looked at the specs. They really do look impressive. 240 cores, each running at almost 2ghz with 4GB of dedicated memory. That's a lot of hardware, especially when you see some "super computers" on sale that have four of them in one machine.
I've been hearing a lot about NVidia's new "super computer on your desk", but all I can really find is marketing talk. I was skeptical of the claims until I went to the site and looked at the specs. They really do look impressive. 240 cores, each running at almost 2ghz with 4GB of dedicated memory. That's a lot of hardware, especially when you see some "super computers" on sale that have four of them in one machine. There's just one thing that I can't figure out...how does it work? According to what little documentation I can find, the system processor offloads work onto the GPUs, but I'm a little fuzzy on how that works. Since there are drivers, maybe they offload intensive work onto the card? I'm not sure, honestly.
Does anyone have any experience with this? We do some large math here that might be handy to offload to a card if it works well enough. A price tag of $1300 is a bit much for me to experiment with at the moment, though.
Wednesday, May 6, 2009
Learning
I've written a little bit about this before, but I wanted to expound on it. Since I'm at the new beta site today, I thought I'd run this instead of the normal blog entry.
Whether or not you endorse the tenets of natural selection, you must admit one thing: human beings are constantly evolving, and not just on a species level. I mean you. Me. We are evolving. We’re changing – different today than yesterday, and the day before. We have new knowledge and experiences. Inherently, we are not the same. Hopefully we have become better, more able to face the challenges of today and tomorrow, and by expanding ourselves, we facilitate further alterations to our beings.
How and why does this happen? Part of it is accidental. New experiences build neural connections in our brains, and we grow. We eventually stop hitting the same pothole on the way to work, because we learn to avoid it. This way we can discover exciting new potholes.
Often the process is intentional. Reading books and manuals, attending classes, building test beds, and implementing new technology forces our brains into overdrive, maps new pathways, and increases the speed by which we will learn in the future.
As IT administrators, we deal with a rapidly changing world that demands our constant improvement. Blink your eyes and things increase by an order of magnitude. Technologies that were up-and-coming fade into obscurity and too often we’re responsible for managing every step in that lifecycle. How do we keep up with it?
It’s easy to give up - to not try. It is almost tempting, actually, to stick with what you know rather than to discover, investigate, and implement newer (and possibly better) technologies, but I urge you to reconsider that option. The less flexible you are, the harder it will be when some inevitable change occurs and leaves you standing in the dust.
In this column, we’re going to examine the types of learning resources that people use in order to improve themselves and their minds. These resources are at your disposal as well. Many of them are inside you as you read this, waiting to be unleashed on unsuspecting information throughout the world. I ask only that you ignore the complacency which gnaws at your soul, holding you back while others move ahead.
Traditional Learning
Throughout thousands of years of human history, advancing in knowledge came from scholarship under an already learned master. Modern society has extended this concept into mass production. Where a master once had a few pupils in apprenticeship, teachers today face an onslaught of students vying for time and attention. Nevertheless, class work can be invaluable in acquiring knowledge, depending on the class (and the professor).
If you are young enough that you are still in school full time, my advice is that you choose your classes wisely. Research the class by interviewing past students of the curriculum and the teacher, and make sure that you understand what the ex-pupil’s goals were for the class. Remember that a review could have been made through the vanilla-tinted lenses of “good enough” by someone who merely wanted to complete class, as opposed to someone who was truly seeking knowledge. Interview people who share your goal of self-improvement.
If you are seeking continuing education classes, you may have an overwhelming number of choices, depending on the subject matter. Not being on any specific campus, finding people to interview may be more difficult, but it is by no means impossible. With the explosion of blogs, chances are excellent that someone on the internet has taken the class. Utilize your favorite search engine to find an ex-student and ask them what they thought. If you aren’t able to find past students, email any address you can find at the institution and attempt to get in touch with your would-be professor. There should be no issue discussing curriculum with you.
Specific web sites are available for reviewing online classes, such as http://www.trainingreviews.com/. There may be a chance that your class has already been reviewed. If your goal is to become certified, you might check the certification homepage on about.com: http://certification.about.com/. Due diligence can save you money and time.
I speak from experience when I recommend that you research the curriculum of a class. A few years ago, I attended an database course which served as an introduction to Oracle 10g. If I had examined the syllabus further than I did, I would have realized that the innstructor assumed a pre-existing knowledge of Oracle, which put me somewhat at a disadvantage, having none. On the other hand, I had a very positive experience while enrolled in the Cisco University for several semesters. It was very well recommended by several of my associates, and jumpstarted my experience by introducing me to several pieces of equipment I had theretofore not touched. Do your research and don’t waste your (or your company’s) money.
Exceptional Learning
As you probably realize, attending class is not the only way to acquire knowledge, even if it is the most traditional. Training comes in many shapes and sizes, much of it deliverable through the postal service or email. The training that costs you thousands of dollars can be reduced to hundreds (or less) by purchasing only the books which normally accompany the training class. This structured-but-open-ended method has been used by many people to pass certification exams, but I have qualms about it. My opinion is that the main benefit of the class is the experience contained within the instructor, and by robbing yourself of the student / teacher relationship, something intangible is lost.
I do not want to make it sound as if structured class learning is the only way, or even the best way. It is “a” way. Just as people learn differently, there are many different ways to learn. We’ve looked at instructor led and structured self-study, but there are more.
If you’re unfamiliar with the term “autodidact”, you’re not alone. An autodidact is an individual who takes the initiative to teach themselves, rather than go through the formal process of education and studying under a professor. Autodidactism, as it is known, has a long history and includes such luminaries as Socrates, Benjamin Franklin, and Thomas Edison. Even Samuel Clemens once famously wrote as Mark Twain, “I have never let my schooling interfere with my education”. Indeed.
To some extent, I think many of us have tendencies such as these. We all learn things by doing and exploring on our own, but through my observations, I have obtained the belief that IT professionals have stronger tendencies than most in this regard. There are always exceptions, but we do generally seek out and explore new things. We tend to be xenophiles by nature, opening ourselves to new experiences and new ideas. When you combine this with the urge to plumb the depths of a subject, you get an autodidact.
If you have ever learned about a new subject, then absorbed that subject top to bottom in order to “own” it, to make it part of you, then you have the makings of an autodidact. If you haven’t, it is not too late to begin now. A great place to start is a subject that you’ve always been curious about but never gotten around to researching. Begin on the internet. Go to the library. Use magazines, books, research papers, and encyclopedias to make that subject your own. Truly grasp that subject, and revel in it.
Absorbing reams of information will absolutely grow new neural pathways, but in order to get neural superhighways, you’ve got to go the extra step. Start learning experientially; which means that instead of merely reading about the subject, you experience it. Find a museum. Go into the field. Reach out and contact people who are on the front lines of discovery. You get vacation days; use them. I’ve studied ancient Egyptology since I was a child, but what I learned when I actually visited and toured privately with an Egyptologist put my reading to shame. Experience is the ultimate teacher.
Share your knowledge
I will finish on a subject that is close to my heart. You have acquired all of this knowledge, this experience, and made these subjects a part of you. Now, pass it on to someone else. We are, each of us, stronger together than we ever could be separately. This fact is not lost on the many, many user groups which exist throughout the world. Individuals have banded together to share their experience and knowledge, to help each other learn, and everyone benefits from this altruism.
Several years ago, I helped establish a Linux Users Group in my home town. Initially, there was a lot of interest; it waned when the people in charge grew preoccupied with bureaucratic aspects rather than information sharing, and the group suffered and eventually went defunct. I have since stuck with attempting to organize people via electronic means such as my blog (http://standalone-sysadmin.blogspot.com). There are still wonderful opportunities for in-person user groups, so don’t let my experience dissuade you from joining or starting your own.
A great alternative if you have trouble locating or starting a group in your area is to join an online community of like-minded people. A good place to start is the The Sysadmin Network, a group of systems administrators who all want to improve their skills and increase their knowledge. Join a formal group, such as LOPSA or SAGE, that encourages you to grow professionally as well as intellectually. Only by pushing the boundaries and aligning yourself with others who strive for the same goals can you reach your maximum potential.
Whether or not you endorse the tenets of natural selection, you must admit one thing: human beings are constantly evolving, and not just on a species level. I mean you. Me. We are evolving. We’re changing – different today than yesterday, and the day before. We have new knowledge and experiences. Inherently, we are not the same. Hopefully we have become better, more able to face the challenges of today and tomorrow, and by expanding ourselves, we facilitate further alterations to our beings.
How and why does this happen? Part of it is accidental. New experiences build neural connections in our brains, and we grow. We eventually stop hitting the same pothole on the way to work, because we learn to avoid it. This way we can discover exciting new potholes.
Often the process is intentional. Reading books and manuals, attending classes, building test beds, and implementing new technology forces our brains into overdrive, maps new pathways, and increases the speed by which we will learn in the future.
As IT administrators, we deal with a rapidly changing world that demands our constant improvement. Blink your eyes and things increase by an order of magnitude. Technologies that were up-and-coming fade into obscurity and too often we’re responsible for managing every step in that lifecycle. How do we keep up with it?
It’s easy to give up - to not try. It is almost tempting, actually, to stick with what you know rather than to discover, investigate, and implement newer (and possibly better) technologies, but I urge you to reconsider that option. The less flexible you are, the harder it will be when some inevitable change occurs and leaves you standing in the dust.
In this column, we’re going to examine the types of learning resources that people use in order to improve themselves and their minds. These resources are at your disposal as well. Many of them are inside you as you read this, waiting to be unleashed on unsuspecting information throughout the world. I ask only that you ignore the complacency which gnaws at your soul, holding you back while others move ahead.
Traditional Learning
Throughout thousands of years of human history, advancing in knowledge came from scholarship under an already learned master. Modern society has extended this concept into mass production. Where a master once had a few pupils in apprenticeship, teachers today face an onslaught of students vying for time and attention. Nevertheless, class work can be invaluable in acquiring knowledge, depending on the class (and the professor).
If you are young enough that you are still in school full time, my advice is that you choose your classes wisely. Research the class by interviewing past students of the curriculum and the teacher, and make sure that you understand what the ex-pupil’s goals were for the class. Remember that a review could have been made through the vanilla-tinted lenses of “good enough” by someone who merely wanted to complete class, as opposed to someone who was truly seeking knowledge. Interview people who share your goal of self-improvement.
If you are seeking continuing education classes, you may have an overwhelming number of choices, depending on the subject matter. Not being on any specific campus, finding people to interview may be more difficult, but it is by no means impossible. With the explosion of blogs, chances are excellent that someone on the internet has taken the class. Utilize your favorite search engine to find an ex-student and ask them what they thought. If you aren’t able to find past students, email any address you can find at the institution and attempt to get in touch with your would-be professor. There should be no issue discussing curriculum with you.
Specific web sites are available for reviewing online classes, such as http://www.trainingreviews.com/. There may be a chance that your class has already been reviewed. If your goal is to become certified, you might check the certification homepage on about.com: http://certification.about.com/. Due diligence can save you money and time.
I speak from experience when I recommend that you research the curriculum of a class. A few years ago, I attended an database course which served as an introduction to Oracle 10g. If I had examined the syllabus further than I did, I would have realized that the innstructor assumed a pre-existing knowledge of Oracle, which put me somewhat at a disadvantage, having none. On the other hand, I had a very positive experience while enrolled in the Cisco University for several semesters. It was very well recommended by several of my associates, and jumpstarted my experience by introducing me to several pieces of equipment I had theretofore not touched. Do your research and don’t waste your (or your company’s) money.
Exceptional Learning
As you probably realize, attending class is not the only way to acquire knowledge, even if it is the most traditional. Training comes in many shapes and sizes, much of it deliverable through the postal service or email. The training that costs you thousands of dollars can be reduced to hundreds (or less) by purchasing only the books which normally accompany the training class. This structured-but-open-ended method has been used by many people to pass certification exams, but I have qualms about it. My opinion is that the main benefit of the class is the experience contained within the instructor, and by robbing yourself of the student / teacher relationship, something intangible is lost.
I do not want to make it sound as if structured class learning is the only way, or even the best way. It is “a” way. Just as people learn differently, there are many different ways to learn. We’ve looked at instructor led and structured self-study, but there are more.
If you’re unfamiliar with the term “autodidact”, you’re not alone. An autodidact is an individual who takes the initiative to teach themselves, rather than go through the formal process of education and studying under a professor. Autodidactism, as it is known, has a long history and includes such luminaries as Socrates, Benjamin Franklin, and Thomas Edison. Even Samuel Clemens once famously wrote as Mark Twain, “I have never let my schooling interfere with my education”. Indeed.
To some extent, I think many of us have tendencies such as these. We all learn things by doing and exploring on our own, but through my observations, I have obtained the belief that IT professionals have stronger tendencies than most in this regard. There are always exceptions, but we do generally seek out and explore new things. We tend to be xenophiles by nature, opening ourselves to new experiences and new ideas. When you combine this with the urge to plumb the depths of a subject, you get an autodidact.
If you have ever learned about a new subject, then absorbed that subject top to bottom in order to “own” it, to make it part of you, then you have the makings of an autodidact. If you haven’t, it is not too late to begin now. A great place to start is a subject that you’ve always been curious about but never gotten around to researching. Begin on the internet. Go to the library. Use magazines, books, research papers, and encyclopedias to make that subject your own. Truly grasp that subject, and revel in it.
Absorbing reams of information will absolutely grow new neural pathways, but in order to get neural superhighways, you’ve got to go the extra step. Start learning experientially; which means that instead of merely reading about the subject, you experience it. Find a museum. Go into the field. Reach out and contact people who are on the front lines of discovery. You get vacation days; use them. I’ve studied ancient Egyptology since I was a child, but what I learned when I actually visited and toured privately with an Egyptologist put my reading to shame. Experience is the ultimate teacher.
Share your knowledge
I will finish on a subject that is close to my heart. You have acquired all of this knowledge, this experience, and made these subjects a part of you. Now, pass it on to someone else. We are, each of us, stronger together than we ever could be separately. This fact is not lost on the many, many user groups which exist throughout the world. Individuals have banded together to share their experience and knowledge, to help each other learn, and everyone benefits from this altruism.
Several years ago, I helped establish a Linux Users Group in my home town. Initially, there was a lot of interest; it waned when the people in charge grew preoccupied with bureaucratic aspects rather than information sharing, and the group suffered and eventually went defunct. I have since stuck with attempting to organize people via electronic means such as my blog (http://standalone-sysadmin.blogspot.com). There are still wonderful opportunities for in-person user groups, so don’t let my experience dissuade you from joining or starting your own.
A great alternative if you have trouble locating or starting a group in your area is to join an online community of like-minded people. A good place to start is the The Sysadmin Network, a group of systems administrators who all want to improve their skills and increase their knowledge. Join a formal group, such as LOPSA or SAGE, that encourages you to grow professionally as well as intellectually. Only by pushing the boundaries and aligning yourself with others who strive for the same goals can you reach your maximum potential.
Tuesday, May 5, 2009
Wahoo! 500+ Subscribers!
I've known for a while that I was getting close, but this morning, Google Reader confirmed it:

Standalone Sysadmin has over 500 subscribers! Wahoo!
For every one of you who reads this, thank you.
I want to especially thank a few other blogs that have sent a ton of visitors my way:
(in order of visitors sent, according to Google Analytics):
Bob Plankers at The Lone Sysadmin
Michael Janke at Last In First Out
Jeff Hengesbach at his blog
Chris Siebenmann at CSpace
Ian Carder at iDogg
Nick Anderson at cmdln.org
Phillip Sellers at Tech Talk
Ryan Nedeff at his blog
I also want to thank the various blog aggregators who have picked me up. I'm probably missing a couple here that I don't know about:
PlanetSysadmin
Sysadmin Blogs /planet
Technorati
LOPSA-NJ
And anyone else who linked to my blog,
Thank you very much!
As always, please drop me a line at standalone.sysadmin@gmail.com with suggestions or feedback of any kind.
Standalone Sysadmin has over 500 subscribers! Wahoo!
For every one of you who reads this, thank you.
I want to especially thank a few other blogs that have sent a ton of visitors my way:
(in order of visitors sent, according to Google Analytics):
Bob Plankers at The Lone Sysadmin
Michael Janke at Last In First Out
Jeff Hengesbach at his blog
Chris Siebenmann at CSpace
Ian Carder at iDogg
Nick Anderson at cmdln.org
Phillip Sellers at Tech Talk
Ryan Nedeff at his blog
I also want to thank the various blog aggregators who have picked me up. I'm probably missing a couple here that I don't know about:
PlanetSysadmin
Sysadmin Blogs /planet
Technorati
LOPSA-NJ
And anyone else who linked to my blog,
Thank you very much!
As always, please drop me a line at standalone.sysadmin@gmail.com with suggestions or feedback of any kind.
Saturday, May 2, 2009
Resizing storage LUNs in Linux on the fly
I'm in the office working today and I figured out the best way (for me, anyway) to resize SAN LUNs without rebooting the server. I figured that I should document it.
To paraphase Linus, Only wimps use internal wikis: _real_ men just document their important stuff on blogs, and let the rest of the world aggregate it ;-)
Alright, the background first. Suppose I've got a SAN storage array, and I've created a LUN (essentially a disk segment) that I've presented to my server. Because I'm intelligent and plan ahead, I'm using LVM to manage it.
Lets say I make 50GB for "data". I make my physical volume on the device (in this case, /dev/sdb1), I create a volume group for it, vgData, and I create a logical volume inside of that one, lvData. I can now make an ext3 filesystem on /dev/vgData/lvData, and mount it to /mnt/data. I run "df -h" and it shows just under 50GB free. Awesome.
Now, I want to expand my 50GB drive. I need another 10GB, so I log into the console on the SAN storage box, and I resize the "data" virtual disk by 10GB. It's now sitting at 60GB. Step 1 complete.
Now, if the world were sane, you could do "fdisk -l /dev/sdb" and see the free space. But it isn't, and you can't. It will still happily report the old size. There are all sorts of google results for changing that, but I've found that none of them will actually do it until you perform the following steps.
Unmount /mnt/data:
# umount /mnt/data
Make the volume group unaccessible:
# vgchange -a n vgData
Unless you perform that last step, the lvm2-monitor service keeps the /dev/sdb1 device open, which means everything that we're going to perform next won't matter. You *HAVE* to stop all access to that disk (at least with the current CentOS kernel).
Now that the filesystem is unmounted and the device isn't in use, issue this command:
# echo "1" > /sys/class/scsi_device/$host:$channel:$id:$lun/device/rescan
where $host:$channel:$id:$lun are whatever combination of scsi path you have to your device. Mine was 2:0:0:0 since it was the first (zero'th?) disk on the 2nd controller. If you do an ls in /sys/class/scsi_device you'll see what is available on your system, and to my knowledge, rescanning the wrong controller won't hurt it, so if you screw up, it's not tragic.
Now if you have done things right, you should be able to run the fdisk -l /dev/sdb and see the new size reflected. Horray!
I fdisk'd in and added a 2nd partition (/dev/sdb2), ran pvcreate on it, extended the volume group on it, used lvextend, and then made it available with vgchange. [Edit] As anonymous mentioned in the comments, pvextend should also work at this point, though I haven't tested it yet. There's no reason it shouldn't.[/Edit] I finally mounted /dev/vgData/lvData and used resize2fs to grow it online. Now a "df -h" returns the "right" number, without ever having to reboot the machine.
Maybe in the future it will be possible to do it while the filesystem is "live", but for now, I'm using this technique since it's better than rebooting.
And if I'm wrong and you CAN do it with a live FS, please let me know. I'm very interested in a better way.
To paraphase Linus, Only wimps use internal wikis: _real_ men just document their important stuff on blogs, and let the rest of the world aggregate it ;-)
Alright, the background first. Suppose I've got a SAN storage array, and I've created a LUN (essentially a disk segment) that I've presented to my server. Because I'm intelligent and plan ahead, I'm using LVM to manage it.
Lets say I make 50GB for "data". I make my physical volume on the device (in this case, /dev/sdb1), I create a volume group for it, vgData, and I create a logical volume inside of that one, lvData. I can now make an ext3 filesystem on /dev/vgData/lvData, and mount it to /mnt/data. I run "df -h" and it shows just under 50GB free. Awesome.
Now, I want to expand my 50GB drive. I need another 10GB, so I log into the console on the SAN storage box, and I resize the "data" virtual disk by 10GB. It's now sitting at 60GB. Step 1 complete.
Now, if the world were sane, you could do "fdisk -l /dev/sdb" and see the free space. But it isn't, and you can't. It will still happily report the old size. There are all sorts of google results for changing that, but I've found that none of them will actually do it until you perform the following steps.
Unmount /mnt/data:
# umount /mnt/data
Make the volume group unaccessible:
# vgchange -a n vgData
Unless you perform that last step, the lvm2-monitor service keeps the /dev/sdb1 device open, which means everything that we're going to perform next won't matter. You *HAVE* to stop all access to that disk (at least with the current CentOS kernel).
Now that the filesystem is unmounted and the device isn't in use, issue this command:
# echo "1" > /sys/class/scsi_device/$host:$channel:$id:$lun/device/rescan
where $host:$channel:$id:$lun are whatever combination of scsi path you have to your device. Mine was 2:0:0:0 since it was the first (zero'th?) disk on the 2nd controller. If you do an ls in /sys/class/scsi_device you'll see what is available on your system, and to my knowledge, rescanning the wrong controller won't hurt it, so if you screw up, it's not tragic.
Now if you have done things right, you should be able to run the fdisk -l /dev/sdb and see the new size reflected. Horray!
I fdisk'd in and added a 2nd partition (/dev/sdb2), ran pvcreate on it, extended the volume group on it, used lvextend, and then made it available with vgchange. [Edit] As anonymous mentioned in the comments, pvextend should also work at this point, though I haven't tested it yet. There's no reason it shouldn't.[/Edit] I finally mounted /dev/vgData/lvData and used resize2fs to grow it online. Now a "df -h" returns the "right" number, without ever having to reboot the machine.
Maybe in the future it will be possible to do it while the filesystem is "live", but for now, I'm using this technique since it's better than rebooting.
And if I'm wrong and you CAN do it with a live FS, please let me know. I'm very interested in a better way.
Friday, May 1, 2009
Random thoughts on Slashdot
I wanted to make a quick reply to someone on slashdot who suggested adding a 5th octet to IP addresses rather than migrating to IPv6. I meant to write a really quick reply, but it got drawn out. I got done with it and thought that some of you might have thoughts on it:
Awesome idea. We'll give Google 1/8, The government can 2/8, IBM will get 3/8, etc etc etc
Same problem. The ipv6 is not a "bad" idea, it's just sort of like...imagine in 1950s if the phone company decided "we could go with area codes to subdivide numbers to prevent running out, or we could use letters AND numbers".
Can you imagine the upheaval?
In a lot of ways, that would have been even easier to deal with, because everyone's phone was owned by AT&T. New phones could have been issued without too much problem.
No, imagine it instead in the mid 1980s. Ma Bell doesn't own the phones any more, in fact there are tons of cheap phones available, cell phones are starting to come out, and there are still rotary AND push button phones.
That's more like what the IPv6 switch is like. Do you give the new people 2 numbers, so that grandma can still call them? How long is it before you stop accepting legacy phones that only have 10 dialing options? How the hell do you get DTMF to work with 36 numbers? Do we need area codes? It would be weird without them, but we don't really need them.
The equivalent of these questions are still being asked. Just a couple of months ago, there was a huge to-do about NAT and IPv6. "IPv6 is a world without NAT". The hell it is. My internal routers don't get publicly routable IP addresses, even if I have to NAT back to IPv4.
When the wrinkles get ironed out, we're going to wonder how we ever did without it. During the transition, it's going to be hell for everyone (with the possible exception of the clueless end user, who might have to buy a new router at most).
Awesome idea. We'll give Google 1/8, The government can 2/8, IBM will get 3/8, etc etc etc
Same problem. The ipv6 is not a "bad" idea, it's just sort of like...imagine in 1950s if the phone company decided "we could go with area codes to subdivide numbers to prevent running out, or we could use letters AND numbers".
Can you imagine the upheaval?
In a lot of ways, that would have been even easier to deal with, because everyone's phone was owned by AT&T. New phones could have been issued without too much problem.
No, imagine it instead in the mid 1980s. Ma Bell doesn't own the phones any more, in fact there are tons of cheap phones available, cell phones are starting to come out, and there are still rotary AND push button phones.
That's more like what the IPv6 switch is like. Do you give the new people 2 numbers, so that grandma can still call them? How long is it before you stop accepting legacy phones that only have 10 dialing options? How the hell do you get DTMF to work with 36 numbers? Do we need area codes? It would be weird without them, but we don't really need them.
The equivalent of these questions are still being asked. Just a couple of months ago, there was a huge to-do about NAT and IPv6. "IPv6 is a world without NAT". The hell it is. My internal routers don't get publicly routable IP addresses, even if I have to NAT back to IPv4.
When the wrinkles get ironed out, we're going to wonder how we ever did without it. During the transition, it's going to be hell for everyone (with the possible exception of the clueless end user, who might have to buy a new router at most).
Thursday, April 30, 2009
Finally, I have a Safari subscription!
After months and months (and months) of asking, FINALLY, my work got me a bookshelf subscription to O'Reilly's Safari Online. If you're unacquainted with this site, click the previous link. It's an online library of IT books from pretty much every major publisher. With my bookshelf subscription, I can "check out" 10 books a month and put them on my "bookshelf", so that they're available to me. With the even cooler "library" subscription, you just go read whatever you want. Your bookshelf doesn't have limits, and it just goes.
Excellent.
A few months ago, I know exactly what I would have checked out first, however I now own the most excellent tome The Practice of Systems and Network Administration. Let me just say that if you don't have it yet, I give it my highest recommendation.
So my question is, what books do you recommend that I get first?
Excellent.
A few months ago, I know exactly what I would have checked out first, however I now own the most excellent tome The Practice of Systems and Network Administration. Let me just say that if you don't have it yet, I give it my highest recommendation.
So my question is, what books do you recommend that I get first?
Wednesday, April 29, 2009
Progressing towards a true backup site
A while back, I moved our production site into a Tier 4 co-location in NJ. Our former primary site became the backup, and things went very smoothly.
Now we're continuing on with our plans of centralizing our company in the northeast of the US. To advance these plans, I'm less than a week away from building a backup site into another tier 4 colo operated by the same company as the primary, but in Philadelphia. This will give us the benefit of being able to lease a fast (100Mb/s) line between the two sites on pre-existing fiber. I cannot tell you how excited I am to be able to have that sort of bandwidth and not rely on T1s.
The most exciting part of this backup site will be that it will use almost exactly the same equipment as the primary site, top to bottom. Back when we were ordering equipment for the primary site, we ordered 2 Dell PowerEdge 1855 enclosures, and we ordered 20 1955s to fill them up. Our SAN storage at the primary is a Dell-branded EMC AX4-5, and we just bought a 2nd for the backup site (though the backup site's storage is only single controller while the primary has redundant controllers. We can always purchase another if we need). We're using the same load balancer as the primary, and we'll have the same Juniper Netscreen firewall configuration. Heck, we're even going to have the same Netgear VPN concentrator. It's going to be a very good thing.
I don't know that I'll have time to create the same sort of diagrams for the rack as I did before, but I should be able to make an adequate spreadsheet of the various pieces of equipment. When all of the pieces are done and in place, I am going to install RackTables to keep track of what is installed where. I mentioned RackTables before on my twitter feed and got some very positive feedback, so if you're looking for a piece of software to keep track of your installed hardware, definitely check that out.
The rest of this week will be spent configuring various network devices. I knocked out the storage array on Monday and two ethernet switches & the fiber switch yesterday. Today I'll be doing the Netscreens, one of the routers (the other will be delivered Friday), and the VPN box. Don't look for extensive updates until next week, when I'll review the install process.
Now we're continuing on with our plans of centralizing our company in the northeast of the US. To advance these plans, I'm less than a week away from building a backup site into another tier 4 colo operated by the same company as the primary, but in Philadelphia. This will give us the benefit of being able to lease a fast (100Mb/s) line between the two sites on pre-existing fiber. I cannot tell you how excited I am to be able to have that sort of bandwidth and not rely on T1s.
The most exciting part of this backup site will be that it will use almost exactly the same equipment as the primary site, top to bottom. Back when we were ordering equipment for the primary site, we ordered 2 Dell PowerEdge 1855 enclosures, and we ordered 20 1955s to fill them up. Our SAN storage at the primary is a Dell-branded EMC AX4-5, and we just bought a 2nd for the backup site (though the backup site's storage is only single controller while the primary has redundant controllers. We can always purchase another if we need). We're using the same load balancer as the primary, and we'll have the same Juniper Netscreen firewall configuration. Heck, we're even going to have the same Netgear VPN concentrator. It's going to be a very good thing.
I don't know that I'll have time to create the same sort of diagrams for the rack as I did before, but I should be able to make an adequate spreadsheet of the various pieces of equipment. When all of the pieces are done and in place, I am going to install RackTables to keep track of what is installed where. I mentioned RackTables before on my twitter feed and got some very positive feedback, so if you're looking for a piece of software to keep track of your installed hardware, definitely check that out.
The rest of this week will be spent configuring various network devices. I knocked out the storage array on Monday and two ethernet switches & the fiber switch yesterday. Today I'll be doing the Netscreens, one of the routers (the other will be delivered Friday), and the VPN box. Don't look for extensive updates until next week, when I'll review the install process.
Sunday, April 26, 2009
The Goodwill Computer Store in Houston, TX
I've been to several Goodwill stores, bothing donating and shopping, and I always see an odd array of old used computer parts. It's a walk down memory lane, usually. I never dreamed that there would be a Goodwill store entirely devoted to computers. Take a look at some of the pictures there. It's unbelievable. I'd love to go there and just walk through. Definitely an old-computer-geek's dream.
Wednesday, April 22, 2009
APC Data Center University
If you're hankering for some free learning and you have any interest at all in data centers, check out the free Data Center University by APC. I registered, but haven't "attended" my first class yet. I'll check it out when I get a little more time, but I just thought some of you might like to know about this, if you didn't already.
Discussion on /. - Should cables be replaced?
Yesterday there was a pretty good discussion going on over at Slashdot regarding changing out network cables. I thought some of you might be interested in it. Sorry for the tardiness, but better late than never, I suppose.
Another thread to add to my SlashDocs bookmarks!
Another thread to add to my SlashDocs bookmarks!
Tuesday, April 21, 2009
My trouble with bonded interfaces
In an effort to improve the redundancy of our network, I have all of our blade servers configured to have bonded network interfaces. Bonding the interfaces in linux means that eth0 and eth1 form together like Voltron into bond0, an interface that can be "high availability", meaning if one physical port (or the device it is plugged into) dies, the other can take over.
Because I wanted to eliminate a single point of failure, I used two switches:
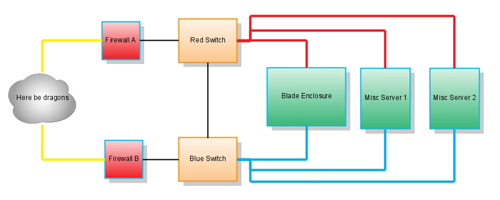
The switches are tied together to make sure traffic on one switch hits the other if necessary.
Here is my problem, though: I have had an array of interesting traffic patterns from my hosts. Some times they'll have occasional intermittent loss of connectivity, sometimes they'll have regular time periods of non-connectivity (both of which I've solved by changing the bonding method), and most recently, I've had the very irritating problem of a host connecting perfectly fine to anything on the local subnet, but remote traffic experiences heavy traffic loss. To fix the problem, all I have to do is unplug one of the network cables.
I've got the machine set up in bonding mode 0. According to the documents, mode 0 is:
It would be at least logical if I lost 50% of the packets. Two interfaces, one malfunctioning, half the packets. But no, it's more like 70% of the packets getting lost, and I haven't managed to figure it out yet.
If you check my twitter feed for yesterday, I was whining about forgetting a jacket. This is because I was hanging out in the colocation running tests. 'tcpdump' shows that the packets are actually being sent. Only occasional responses are received, though, unless the other host is local, in which case everything is fine.
There are several hosts configured identically to this one, however this is the only one displaying this issue. Normally I'd suspect the firewall, but there isn't anything in the configuration that would single out this machine, and the arp tables check out everywhere. I'm confused, but I haven't given up yet. I'll let you know if I figure it out, and in the mean time, if you've got suggestions, I'm open to them.
Because I wanted to eliminate a single point of failure, I used two switches:
The switches are tied together to make sure traffic on one switch hits the other if necessary.
Here is my problem, though: I have had an array of interesting traffic patterns from my hosts. Some times they'll have occasional intermittent loss of connectivity, sometimes they'll have regular time periods of non-connectivity (both of which I've solved by changing the bonding method), and most recently, I've had the very irritating problem of a host connecting perfectly fine to anything on the local subnet, but remote traffic experiences heavy traffic loss. To fix the problem, all I have to do is unplug one of the network cables.
I've got the machine set up in bonding mode 0. According to the documents, mode 0 is:
Round-robin policy: Transmit packets in sequential
order from the first available slave through the
last. This mode provides load balancing and fault
tolerance.
It would be at least logical if I lost 50% of the packets. Two interfaces, one malfunctioning, half the packets. But no, it's more like 70% of the packets getting lost, and I haven't managed to figure it out yet.
If you check my twitter feed for yesterday, I was whining about forgetting a jacket. This is because I was hanging out in the colocation running tests. 'tcpdump' shows that the packets are actually being sent. Only occasional responses are received, though, unless the other host is local, in which case everything is fine.
There are several hosts configured identically to this one, however this is the only one displaying this issue. Normally I'd suspect the firewall, but there isn't anything in the configuration that would single out this machine, and the arp tables check out everywhere. I'm confused, but I haven't given up yet. I'll let you know if I figure it out, and in the mean time, if you've got suggestions, I'm open to them.
Monday, April 20, 2009
Sysadmin Aphorisms
I ran across this great list of Sysadmin Aphorisms. Give it a quick read through, as there are (I think) some thought provoking statements.
What would you add?
What would you add?
I see in my future...
Fixing recurring problems, working on new storage implementation, and ordering/configuration of new networking gear.
I'm getting ready to build out our "beta" site, as in, secondary, behind the currently-live "alpha" site. The 10 blades are mostly configured (and since they take 208v electricity, they're as configured as they're going to get until the rack gets turned up). I've got the AX4-5 to partition as well. I remember the procedure pretty well from the alpha config. We were very lucky to be able to get the same piece of kit for both sites. We had been looking at AoE and iSCSI, but CDW sold us the AX4-5 for considerably less than Dell was asking. And the front bezel is prettier to boot.
I'm also going to need to pick up a couple of Ciscos. Since my networking needs are light, I prefer to get refurbished routers. I'll be needing two fast ethernet ports, to 2621's will be perfect.
The recurring problem is sort of interesting. Every once in a while, the host will stop responding to packets. My kneejerk response was 'bad network cable', but the machine has two bonded interfaces. One bad cable wouldn't cause that, and nothing else on the switch is experiencing the same symptoms. I'm going to head into the colocation to try and figure out what's going on. If the resolution is at all unique, I'll post about it here.
I'm getting ready to build out our "beta" site, as in, secondary, behind the currently-live "alpha" site. The 10 blades are mostly configured (and since they take 208v electricity, they're as configured as they're going to get until the rack gets turned up). I've got the AX4-5 to partition as well. I remember the procedure pretty well from the alpha config. We were very lucky to be able to get the same piece of kit for both sites. We had been looking at AoE and iSCSI, but CDW sold us the AX4-5 for considerably less than Dell was asking. And the front bezel is prettier to boot.
I'm also going to need to pick up a couple of Ciscos. Since my networking needs are light, I prefer to get refurbished routers. I'll be needing two fast ethernet ports, to 2621's will be perfect.
The recurring problem is sort of interesting. Every once in a while, the host will stop responding to packets. My kneejerk response was 'bad network cable', but the machine has two bonded interfaces. One bad cable wouldn't cause that, and nothing else on the switch is experiencing the same symptoms. I'm going to head into the colocation to try and figure out what's going on. If the resolution is at all unique, I'll post about it here.
Thursday, April 16, 2009
And you thought the fan was bad...
The other day, I posted some photos of a fan hanging from the rafters. Those pictures have nothing on these:
Parks Hall Server Room Fire. This happened in July of 2002 and was apparently caused by an electrical problem in one of the old servers. Here is a news article on it.
I just don't have words that would express my disbelief. wow.
If there is any bright side, the staff at UWW produced an in-depth paper on the disaster recovery and rebuilding process. It's a good read, and a very sobering thought that something like this could easily happen to any of us.
If you ever wanted an argument for off-site backups, there you go.
Parks Hall Server Room Fire. This happened in July of 2002 and was apparently caused by an electrical problem in one of the old servers. Here is a news article on it.
I just don't have words that would express my disbelief. wow.
If there is any bright side, the staff at UWW produced an in-depth paper on the disaster recovery and rebuilding process. It's a good read, and a very sobering thought that something like this could easily happen to any of us.
If you ever wanted an argument for off-site backups, there you go.
Wednesday, April 15, 2009
Future (or current?) replacement for Nagios?
I was unaware of this project, but thanks to stephenpc on twitter, I read an excellent (if a bit dated) article on RootDev which brought OpenNMS to my attention as a possible replacement for nagios.
I was mildly surprised, mostly because I haven't been shopping for a Nagios replacement since I installed and configured Nagios 3. I had looked at Zenoss as a possibility, but decided to stick with Nagios since I was already familiar with the configuration routine (and 3.x had some great improvements in that regard).
Judging by Craig's comments in that article, openNMS solves problems that I don't have, like so many hosts or services that you can't get to the bottom of the summary page without it refreshing. That's a problem I'm glad I don't have, but I know that some of you run very large networks. So my question would be, what do you large-network guys use for monitoring? And if you have a small network, do you use monitoring? I remember back to the time before I knew about monitoring solutions like Nagios, and it scares me to death. I would actually manually check on important services to make sure they were up, and that was my only way of doing it.
Of course, in my defense I was young and naive then, and didn't even backup things to tape. Ah, the folly of youth.
I was mildly surprised, mostly because I haven't been shopping for a Nagios replacement since I installed and configured Nagios 3. I had looked at Zenoss as a possibility, but decided to stick with Nagios since I was already familiar with the configuration routine (and 3.x had some great improvements in that regard).
Judging by Craig's comments in that article, openNMS solves problems that I don't have, like so many hosts or services that you can't get to the bottom of the summary page without it refreshing. That's a problem I'm glad I don't have, but I know that some of you run very large networks. So my question would be, what do you large-network guys use for monitoring? And if you have a small network, do you use monitoring? I remember back to the time before I knew about monitoring solutions like Nagios, and it scares me to death. I would actually manually check on important services to make sure they were up, and that was my only way of doing it.
Of course, in my defense I was young and naive then, and didn't even backup things to tape. Ah, the folly of youth.
The lord answers prayers
And apparently so does docwhat.
Since I began to get really proficient at vi(m), I started to wish that Netscape (then Mozilla (and now Firefox) ) had a plugin for vi-style editing of text boxes. Oh, how I searched and searched.
Today, I found something nearly as good. Better in a lot of ways, really. It's called It's All Text!, a firefox extension that allows you to launch your favorite editor to populate a textbox. Just save the document that you're typing, and voila! The text goes into the box.
I used gvim to type this entire blog entry. If I can figure out a way to get it to launch automatically whenever I click in a text box, I might be able to die a happy man.
Since I began to get really proficient at vi(m), I started to wish that Netscape (then Mozilla (and now Firefox) ) had a plugin for vi-style editing of text boxes. Oh, how I searched and searched.
Today, I found something nearly as good. Better in a lot of ways, really. It's called It's All Text!, a firefox extension that allows you to launch your favorite editor to populate a textbox. Just save the document that you're typing, and voila! The text goes into the box.
I used gvim to type this entire blog entry. If I can figure out a way to get it to launch automatically whenever I click in a text box, I might be able to die a happy man.
Tuesday, April 14, 2009
Testing Disk Speed
If you've got network storage, whether NAS or SAN, you probably care how fast it is.
There are a lot of ways to increase speed, such as choosing the right RAID level, making sure you have the right spindle count. (Incidentally, I found a very interesting, if somewhat lacking, RAID estimator that is fun to play with. I just wish they supported more RAID levels...)
Anyway, you want to design your storage to go fast. But how do you test it? Josh Berkus suggests using 'dd' in Unix to test the speed of the writes and reads from disk.
I've used this technique, but without the additional step of clearing the memory cache by writing a file as large as the machine's memory. I don't know if it's guaranteed to work in all cases, but it's a good idea to account for that.
Anyone else have a better more "official" way to calculate read/write speeds?
[UPDATE]
As non4top mentioned in the comments, bonnie++ is a well known program for viewing speed. Funnily enough, it was written by Russell Coker, who has a blog that I read quite often. Iozone also seems to be pretty popular according to Dave, and I can see why from those graphs :-)
If you're interested, here's a longer list of drive benchmark software.
There are a lot of ways to increase speed, such as choosing the right RAID level, making sure you have the right spindle count. (Incidentally, I found a very interesting, if somewhat lacking, RAID estimator that is fun to play with. I just wish they supported more RAID levels...)
Anyway, you want to design your storage to go fast. But how do you test it? Josh Berkus suggests using 'dd' in Unix to test the speed of the writes and reads from disk.
I've used this technique, but without the additional step of clearing the memory cache by writing a file as large as the machine's memory. I don't know if it's guaranteed to work in all cases, but it's a good idea to account for that.
Anyone else have a better more "official" way to calculate read/write speeds?
[UPDATE]
As non4top mentioned in the comments, bonnie++ is a well known program for viewing speed. Funnily enough, it was written by Russell Coker, who has a blog that I read quite often. Iozone also seems to be pretty popular according to Dave, and I can see why from those graphs :-)
If you're interested, here's a longer list of drive benchmark software.
Monday, April 13, 2009
HOWTO: RedHat Cluster Suite
Alright, here it is, my writeup on RHCS. Before I continue, I need to remind you that, as I mentioned before, I had to pull the plug on it. I never got it working reliably so that a failure wouldn't bring down the entire cluster, and from the comments in that thread, I'm not alone.
This documentation is provided for working with the RedHat Cluster Suite that shipped with RHEL/CentOS 5.2. It is important to keep this in mind, because if you are working with a newer version, there may be major changes. This has already happened before with the 4.x-5.x switch, rendering most of the documentation on the internet deprecated at best, and destructive at worst. The single most helpful document I found was this: The Red Hat Cluster Suite NFS Cookbook, and even with that, you will notice the giant "Draft Copy" watermark. I haven't found anything to suggest that it was ever revised past "draft" form.
In my opinion, RedHat Cluster Suite is not ready for "prime time", and even in the words of a developer from #linux-cluster, "I don't know if I would use 5.2 stock release with production data". That being said, you might be interested in playing around with it, or you might choose to ignore my warnings and try it on production systems. If it's the latter, please do yourself a favor and have a backup plan. I know from experience that it's no fun to rip out a cluster configuration and try to set up discrete fileservers.
Alright, that's enough of a warning I think. Lets overview what RHCS does.
RedHat Cluster Suite is designed to allow High Availability (HA) services, as opposed to a compute cluster which gives you the benefit of parallel processing. If you're rendering movies, you want a compute cluster. If you want to make sure that your fileserver is always available, you want an HA cluster.
The general idea of RHCS is that you have a number of servers (nodes), hopefully at least 3, but 2 is possible but not recommended. Each of those machines is configured identically and has the cluster configuration distributed to it. The "cluster manager" (cman) keeps track of who all is a member of the cluster. The Cluster Configuration System (ccs) makes sure that all cluster nodes have the same configuration. The resource manager (rgmanager) makes sure that your configured resources are available on each node, the Clustered Logical Volume Manager (clvmd) makes sure that everyone agrees that disks are available to the cluster, and the lock manager (dlm (distributed lock manager) or gulm (grand unified lock manager (deprecated))) ensures that your filesystems' integrity is maintained across the cluster. Sounds simple, right? Right.
Alright, so lets make sure the suite is installed. Easiest way is to make sure the Clustering and Cluster Storage options are selected at install or in system-config-packages. Note: if you have a standard RedHat Enterprise license, you'll need to pony up over a thousand dollars more per year per node to get the clustering options. The benefit of this is that you get support from Redhat, the value of which I have heard questioned by several people. Or you could just install CentOS, which is a RHEL-clone. I can't recommend Fedora, just because Redhat seems to test things out there as opposed to RHEL (and CentOS) which only gets "proven" software. Unless you're talking about perl, but I digress.
So the software is installed, terrific. Lets discuss your goals now. It is possible, though not very useful, to have a cluster configured without any resources. Typically you will want at least one shared IP address. In this case, the active node will have the IP, and whenever the active node changes, the IP will move with it. This is as good a time as any to mention that you won't be able to see this IP when you run 'ifconfig'. You've got to find it with 'ip addr list'.
Aside from a common IP address, you'll probably want to have a shared filesystem. Depending on what other services your cluster will be providing, it might be possible to get away with having them all mount a remote NFS share. You'll have to determine whether your service will work reliably over NFS on your own. Here's a hint: vmware server won't, because of the way NFS locks files (At least I haven't gotten it to work since I last tried a few months ago. YMMV).
Regardless, we'll assume you're not able to use NFS, and you've got to have a shared disk. This is accomplished by using a Storage Area Network (SAN), most commonly. Setting up and configuring your SAN is beyond the scope of this entry, but the key point is that all of your cluster nodes have to have equal access to the storage resources. Once you've assigned that access in the storage configuration, make sure that each machine can see the volumes that it is supposed to have access to.
After you've verified that all the volumes can be accessed by all of the servers, filesystems must be created. I cannot recommend LVM highly enough. I created an introduction to LVM a last year to help understand the concept and why you want to use it. Use this knowledge and the LVM Howto to create your logical volumes. Alternately, system-config-lvm is a viable gui alternative, although the interface takes some getting used to. When creating volume groups, make sure that the clustered flag is set to yes. This will stop them from showing up when the node isn't connected to the cluster, such as right after booting up.
To make sure that the lock manager can deal with the filesystems, on all hosts, you must also edit the LVM configuration (typically /etc/lvm/lvm.conf) to change "locking_type = 1" to "locking_type = 3", which tells LVM to use clustered locking. Restart LVM processes with 'service lvm2-monitor restart'.
Now, lets talk about the actual configuration file. cluster.conf is an XML file that's separated by tags into sections. Each of these sections is housed under the "cluster" tag.
Here is the content of my file, as an example:
If you read carefully, most of the entries can be self explained, but we'll go over the broad strokes.
The first line names the cluster. It also has a "config_version" property. This config_version value is used to decide which cluster node has the most up-to-date configuration. In addition, if you edit the file and try to redistribute it without incrementing the value, you'll get an error, because the config_versions are the same but the contents are different. Always remember to increment the config_version.
The next line is a single entry (you can tell from the trailing /) which defines the fence daemon. Fencing in a cluster is a means to disable a machine from accessing cluster resources. The reason behind this is that if a node goes rogue, detaches itself from the other cluster members, and unilaterally decides that it is going to have read-write access to the data, then the data will end up corrupt. The actual cluster master will be writing to the data at the same time the rogue node will, and that is a Very Bad Thing(tm). To prevent this, all nodes are setup so that they are able to "fence" other nodes that disconnect from the group. The post fail delay in my config means "wait 30 seconds before killing a node". How to do this is going to be talked about later in the fencedevices section.
The post_join_delay is misnamed and should really be called post_create_delay, since the only time it is used is when the cluster is started (as in, there is no running node, and the first machine is turned on). The default action of RHCS is to wait 6 seconds after being started, and to "fence" any nodes listed in the configuration who haven't connected yet. I've increased this value to 30 seconds. The best solution is to never start the cluster automatically after booting. This allows you to manually startup cluster services, which can prevent unnecessary fencing of machines.
Fencing is by far what gave me the most problem.
The next section is clusternodes. This section defines each of the nodes that will be connecting to this cluster. The name will be what you refer to the nodes by using the command line tools, the node ID will be used in the logs and internal referencing, and "votes" has to do with an idea called "quorum". The quorum is the number of nodes necessary to operate a cluster. Typically it's more than 50% of the total number of nodes. In a three-node cluster, it's 2. This is the reason that two node clusters are tricky: by dictating a quorum of 1, you are telling rogue cluster nodes that they should assume they are the active node. Not good. If you find yourself in the unenviable position of only having 2 possible nodes, you need to use a quorum disk.
Inside each cluster node declaration, you need to specify a fence device. The fence device is the method used by fenced (the fencing daemon) to turn off the remote node. Explaining the various methods is beyond this document, but read the fencing documentation for details, and hope not much has changed in the software since they wrote the docs.
After clusternodes, the cman (cluster manager) line dictates the quorum (called "expected_votes") and two_node="0", which means "this isn't a two node cluster".
The next section is the fencedevices declaration. Since I was using dell poweredge blades, I used the fence_drac agent, which has DRAC specific programming to turn off nodes. Check the above-linked-documentation for your solution.
<rm> stands for Resource Manager, and is where we will declare which resources exist, and where they will be assigned and deployed.
failoverdomains are the list of various groups of cluster nodes. These should be created based on the services that your clusters will share. Since I was only clustering my three file servers, I only had one failover domain. If I wanted to cluster my web servers, I would have created a 2nd failover domain (in addition to creating the nodes in the upper portion of the file, as well). You'll see below in the services section where the failoverdomain comes into effect.
In the resources list, you create "shortcuts" to things that you'll reference later. I'm doing NFS, so I've got to create resources for the filesystems I'll be exporting (the lines that start with cluisterfs), and since I want my exports to be secure, I create a list of clients that will have access to the NFS exports (all others will be blocked). I also create a script that will make changes to SSH and allow me to keep my keys stable over all three machines.
After the resources are declared, we begin the service specification. The IP address is set up, sshd is invoked, samba is started, and the various clusterfs entries are configured. All pretty straightforward here.
Now that we've gone through the configuration file, lets explain some of the underlying implementation. You notice that the configuration invoked the script /etc/init.d/sshd. As you probably know, that is the startup/shutdown script for sshd, which is typically started during the init for multiuser networked runlevels (3 and 5 in RH machines). Since we're starting it now, that would seem to imply that it wasn't running beforehand, however that is not the case. Actually, I had replaced /etc/init.d/sshd with a cluster-aware version that pointed various key files to the clustered filesystems. Here are the changes:
# Begin cluster-ssh modifications
if [ -z "$OCF_RESKEY_service_name" ]; then
#
# Normal / system-wide ssh configuration
#
RSA1_KEY=/etc/ssh/ssh_host_key
RSA_KEY=/etc/ssh/ssh_host_rsa_key
DSA_KEY=/etc/ssh/ssh_host_dsa_key
PID_FILE=/var/run/sshd.pid
else
#
# Per-service ssh configuration
#
RSA1_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_key
RSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_rsa_key
DSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_dsa_key
PID_FILE=/var/run/sshd-$OCF_RESKEY_service_name.pid
CONFIG_FILE="/etc/cluster/ssh/$OCF_RESKEY_service_name/sshd_config"
[ -n "$CONFIG_FILE" ] && OPTIONS="$OPTIONS -f $CONFIG_FILE"
prog="$prog ($OCF_RESKEY_service_name)"
fi
[ -n "$PID_FILE" ] && OPTIONS="$OPTIONS -o PidFile=$PID_FILE"
# End cluster-ssh modifications
I got these changes from this wiki entry, and it seemed to work stably, even if the rest of the cluster didn't always.
You'll also notice that I specify all the things in the services section that normally exist in /etc/exports. That file isn't used in RHCS-clustered NFS. The equivalent of exports is generated on the fly by the cluster system. This implies that you should turn off the NFS daemon and let the cluster manager handle it.
When it comes to Samba, you're going to need to create configurations for the cluster manager to point to, since the configs aren't generated on the fly like NFS. The naming scheme is /etc/samba/smb.conf.SHARENAME, so in the case of Operations above, I used /etc/samba/smb.conf.Operations. I believe that rgmanager (resource group manager) automatically creates a template for you to edit, but be aware that it takes a particular naming scheme.
Assuming you've created cluster aware LVM volumes (you did read the howto I linked to earlier, right?), you'll undoubtedly want to create a filesystem. GFS is the most common filesystem for RHCS, and can be made using 'mkfs.gfs2', but before you start making filesystems willy-nilly, you should know a few things.
First, GFS2 is a journaled filesystem, meaning that data that will be written to disk is written to a scratch pad first (the scratch pad is called a journal), then copied from the scratch pad to the disk, thus if access to the disk is lost while writing to the filesystem, it can be recopied from the journal.
Each node that will have write access to the GFS2 volume needs to have its own scratch pad. If you've got a 3 node cluster, that means you need three journals. If you've got 3 and you're going to be adding 2 more, just make 5 and save yourself a headache. The number of journals can be altered later (using gfs2_jadd), but just do it right the first time.
For more information on creating and managing gfs2, check the Redhat docs.
I should also throw in a note about lock managers here. Computer operating systems today are inherently multitasking. Whenever one program starts to write to a file, a lock is produced which prevents (hopefully) other programs from writing to the same file. To replicate that functionality in a cluster, you use a "lock manager". The old standard was GULM, the Grand Unified Lock Manager. It was replaced by "DLM", the Distributed Lock Manager. If you're reading documentation that openly suggests GULM, you're reading very old documentation and should probably look for something newer.
Once you've got your cluster configured, you probably want to start it. Here's the order I turned things on in:
# starts the cluster manager
service cman start
# starts the clustered LVM daemon
service clvmd start
# mounts the clustered filesystems (after clvmd has been started)
mount -a
# starts the resource manager, which turns on the various services, etc
service rmanager start
I've found that running these in that order will sometimes work and sometimes they'll hang. If it hangs, it's waiting to find other nodes. To remedy that, I try to start the cluster on all nodes at the same time. Also, if you don't the post_join_delay will bite your butt and fence the other nodes.
Have no false assumptions that this will work the first time. Or the second. As you can see, I made it to my 81st configuration before I gave up, and I did a fair bit of research between versions. Make liberal use of your system logs, which will point to reasons that your various cluster daemons are failing, and try to divine the reasons.
Assuming that your cluster is up and running, you can check on the status with clustat. Move the services with clusvcadm, and manuallyfence nodes with fence_manual. Expect to play a lot, and give yourself a lot of time to play and test. Test Test Test. Once your cluster is stable, try to break it. Unplug machines, network cables, and so on, watching logs to see what happens, when, and why. Use all the documentation you can find, but keep in mind that it may be old.
The biggest source of enlightenment (especially to how screwed I was) came from the #linux-cluster channel on IRC. There are mailing lists, as well, and if you're really desperate, drop me a line and I'll try to find you help.
So that's it. A *long* time in the making, without a happy ending, but hopefully I can help someone else. Drop a comment below regaling me with stories of your great successes (or if RHCS drove you to drink, let me know that too!).
Thanks for reading!
This documentation is provided for working with the RedHat Cluster Suite that shipped with RHEL/CentOS 5.2. It is important to keep this in mind, because if you are working with a newer version, there may be major changes. This has already happened before with the 4.x-5.x switch, rendering most of the documentation on the internet deprecated at best, and destructive at worst. The single most helpful document I found was this: The Red Hat Cluster Suite NFS Cookbook, and even with that, you will notice the giant "Draft Copy" watermark. I haven't found anything to suggest that it was ever revised past "draft" form.
In my opinion, RedHat Cluster Suite is not ready for "prime time", and even in the words of a developer from #linux-cluster, "I don't know if I would use 5.2 stock release with production data". That being said, you might be interested in playing around with it, or you might choose to ignore my warnings and try it on production systems. If it's the latter, please do yourself a favor and have a backup plan. I know from experience that it's no fun to rip out a cluster configuration and try to set up discrete fileservers.
Alright, that's enough of a warning I think. Lets overview what RHCS does.
RedHat Cluster Suite is designed to allow High Availability (HA) services, as opposed to a compute cluster which gives you the benefit of parallel processing. If you're rendering movies, you want a compute cluster. If you want to make sure that your fileserver is always available, you want an HA cluster.
The general idea of RHCS is that you have a number of servers (nodes), hopefully at least 3, but 2 is possible but not recommended. Each of those machines is configured identically and has the cluster configuration distributed to it. The "cluster manager" (cman) keeps track of who all is a member of the cluster. The Cluster Configuration System (ccs) makes sure that all cluster nodes have the same configuration. The resource manager (rgmanager) makes sure that your configured resources are available on each node, the Clustered Logical Volume Manager (clvmd) makes sure that everyone agrees that disks are available to the cluster, and the lock manager (dlm (distributed lock manager) or gulm (grand unified lock manager (deprecated))) ensures that your filesystems' integrity is maintained across the cluster. Sounds simple, right? Right.
Alright, so lets make sure the suite is installed. Easiest way is to make sure the Clustering and Cluster Storage options are selected at install or in system-config-packages. Note: if you have a standard RedHat Enterprise license, you'll need to pony up over a thousand dollars more per year per node to get the clustering options. The benefit of this is that you get support from Redhat, the value of which I have heard questioned by several people. Or you could just install CentOS, which is a RHEL-clone. I can't recommend Fedora, just because Redhat seems to test things out there as opposed to RHEL (and CentOS) which only gets "proven" software. Unless you're talking about perl, but I digress.
So the software is installed, terrific. Lets discuss your goals now. It is possible, though not very useful, to have a cluster configured without any resources. Typically you will want at least one shared IP address. In this case, the active node will have the IP, and whenever the active node changes, the IP will move with it. This is as good a time as any to mention that you won't be able to see this IP when you run 'ifconfig'. You've got to find it with 'ip addr list'.
Aside from a common IP address, you'll probably want to have a shared filesystem. Depending on what other services your cluster will be providing, it might be possible to get away with having them all mount a remote NFS share. You'll have to determine whether your service will work reliably over NFS on your own. Here's a hint: vmware server won't, because of the way NFS locks files (At least I haven't gotten it to work since I last tried a few months ago. YMMV).
Regardless, we'll assume you're not able to use NFS, and you've got to have a shared disk. This is accomplished by using a Storage Area Network (SAN), most commonly. Setting up and configuring your SAN is beyond the scope of this entry, but the key point is that all of your cluster nodes have to have equal access to the storage resources. Once you've assigned that access in the storage configuration, make sure that each machine can see the volumes that it is supposed to have access to.
After you've verified that all the volumes can be accessed by all of the servers, filesystems must be created. I cannot recommend LVM highly enough. I created an introduction to LVM a last year to help understand the concept and why you want to use it. Use this knowledge and the LVM Howto to create your logical volumes. Alternately, system-config-lvm is a viable gui alternative, although the interface takes some getting used to. When creating volume groups, make sure that the clustered flag is set to yes. This will stop them from showing up when the node isn't connected to the cluster, such as right after booting up.
To make sure that the lock manager can deal with the filesystems, on all hosts, you must also edit the LVM configuration (typically /etc/lvm/lvm.conf) to change "locking_type = 1" to "locking_type = 3", which tells LVM to use clustered locking. Restart LVM processes with 'service lvm2-monitor restart'.
Now, lets talk about the actual configuration file. cluster.conf is an XML file that's separated by tags into sections. Each of these sections is housed under the "cluster" tag.
Here is the content of my file, as an example:
<cluster alias="alpha-fs" config_version="81" name="alpha-fs">
<fence_daemon clean_start="1" post_fail_delay="30" post_join_delay="30"/>
<clusternodes>
<clusternode name="fs1.int.dom" nodeid="1" votes="1">
<fence>
<method name="1">
<device modulename="Server-2" name="blade-enclosure"/>
</method>
</fence>
</clusternode>
<clusternode name="fs2.int.dom" nodeid="2" votes="1">
<fence>
<method name="1">
<device modulename="Server-3" name="blade-enclosure"/>
</method>
</fence>
</clusternode>
<clusternode name="fs3.int.dom" nodeid="3" votes="1">
<fence>
<method name="1">
<device modulename="Server-6" name="blade-enclosure"/>
</method>
</fence>
</clusternode>
</clusternodes>
<cman expected_votes="3" two_node="0"/>
<fencedevices>
<fencedevice agent="fence_drac" ipaddr="10.x.x.4" login="root" name="blade-enclosure" passwd="XXXXX"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="alpha-fail1">
<failoverdomainnode name="fs1.int.dom" priority="1"/>
<failoverdomainnode name="fs2.int.dom" priority="2"/>
<failoverdomainnode name="fs3.int.dom" priority="3"/>
</failoverdomain>
</failoverdomains>
<resources>
<clusterfs device="/dev/vgDeploy/lvDeploy" force_unmount="0" fsid="55712" fstype="gfs" mountpoint="/mnt/deploy" name="deployFS"/>
<nfsclient name="app1" options="ro" target="10.x.x.26"/>
<nfsclient name="app2" options="ro" target="10.x.x.27"/>
<clusterfs device="/dev/vgOperations/lvOperations" force_unmount="0" fsid="5989" fstype="gfs" mountpoint="/mnt/operations" name="operationsFS" options=""/>
<clusterfs device="/dev/vgWebsite/lvWebsite" force_unmount="0" fsid="62783" fstype="gfs" mountpoint="/mnt/website" name="websiteFS" options=""/>
<clusterfs device="/dev/vgUsr2/lvUsr2" force_unmount="0" fsid="46230" fstype="gfs" mountpoint="/mnt/usr2" name="usr2FS" options=""/>
<clusterfs device="/dev/vgData/lvData" force_unmount="0" fsid="52227" fstype="gfs" mountpoint="/mnt/data" name="dataFS" options=""/>
<nfsclient name="ops1" options="rw" target="10.x.x.28"/>
<nfsclient name="ops2" options="rw" target="10.x.x.29"/>
<nfsclient name="ops3" options="rw" target="10.x.x.30"/>
<nfsclient name="preview" options="rw" target="10.x.x.42"/>
<nfsclient name="ftp1" options="rw" target="10.x.x.32"/>
<nfsclient name="ftp2" options="rw" target="10.x.x.33"/>
<nfsclient name="sys1" option="rw" target="10.x.x.31"/>
<script name="sshd" file="/etc/init.d/sshd"/>
</resources>
<service autostart="1" domain="alpha-fail1" name="nfssvc">
<ip address="10.x.x.50" monitor_link="1"/>
<script ref="sshd"/>
<smb name="Operations" workgroup="int.dom"/>
<clusterfs ref="deployFS">
<nfsexport name="deploy">
<nfsclient ref="app1"/>
<nfsclient ref="app2"/>
</nfsexport>
</clusterfs>
<clusterfs ref="operationsFS">
<nfsexport name="operations">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
</nfsexport>
</clusterfs>
<clusterfs ref="websiteFS">
<nfsexport name="website">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
<nfsclient ref="preview"/>
</nfsexport>
</clusterfs>
<clusterfs ref="usr2FS">
<nfsexport name="usr2">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
</nfsexport>
</clusterfs>
<clusterfs ref="dataFS">
<nfsexport name="data">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
<nfsclient ref="ftp1"/>
<nfsclient ref="ftp2"/>
<nfsclient ref="sys1"/>
</nfsexport>
</clusterfs>
</service>
</rm>
</cluster>
If you read carefully, most of the entries can be self explained, but we'll go over the broad strokes.
The first line names the cluster. It also has a "config_version" property. This config_version value is used to decide which cluster node has the most up-to-date configuration. In addition, if you edit the file and try to redistribute it without incrementing the value, you'll get an error, because the config_versions are the same but the contents are different. Always remember to increment the config_version.
The next line is a single entry (you can tell from the trailing /) which defines the fence daemon. Fencing in a cluster is a means to disable a machine from accessing cluster resources. The reason behind this is that if a node goes rogue, detaches itself from the other cluster members, and unilaterally decides that it is going to have read-write access to the data, then the data will end up corrupt. The actual cluster master will be writing to the data at the same time the rogue node will, and that is a Very Bad Thing(tm). To prevent this, all nodes are setup so that they are able to "fence" other nodes that disconnect from the group. The post fail delay in my config means "wait 30 seconds before killing a node". How to do this is going to be talked about later in the fencedevices section.
The post_join_delay is misnamed and should really be called post_create_delay, since the only time it is used is when the cluster is started (as in, there is no running node, and the first machine is turned on). The default action of RHCS is to wait 6 seconds after being started, and to "fence" any nodes listed in the configuration who haven't connected yet. I've increased this value to 30 seconds. The best solution is to never start the cluster automatically after booting. This allows you to manually startup cluster services, which can prevent unnecessary fencing of machines.
Fencing is by far what gave me the most problem.
The next section is clusternodes. This section defines each of the nodes that will be connecting to this cluster. The name will be what you refer to the nodes by using the command line tools, the node ID will be used in the logs and internal referencing, and "votes" has to do with an idea called "quorum". The quorum is the number of nodes necessary to operate a cluster. Typically it's more than 50% of the total number of nodes. In a three-node cluster, it's 2. This is the reason that two node clusters are tricky: by dictating a quorum of 1, you are telling rogue cluster nodes that they should assume they are the active node. Not good. If you find yourself in the unenviable position of only having 2 possible nodes, you need to use a quorum disk.
Inside each cluster node declaration, you need to specify a fence device. The fence device is the method used by fenced (the fencing daemon) to turn off the remote node. Explaining the various methods is beyond this document, but read the fencing documentation for details, and hope not much has changed in the software since they wrote the docs.
After clusternodes, the cman (cluster manager) line dictates the quorum (called "expected_votes") and two_node="0", which means "this isn't a two node cluster".
The next section is the fencedevices declaration. Since I was using dell poweredge blades, I used the fence_drac agent, which has DRAC specific programming to turn off nodes. Check the above-linked-documentation for your solution.
<rm> stands for Resource Manager, and is where we will declare which resources exist, and where they will be assigned and deployed.
failoverdomains are the list of various groups of cluster nodes. These should be created based on the services that your clusters will share. Since I was only clustering my three file servers, I only had one failover domain. If I wanted to cluster my web servers, I would have created a 2nd failover domain (in addition to creating the nodes in the upper portion of the file, as well). You'll see below in the services section where the failoverdomain comes into effect.
In the resources list, you create "shortcuts" to things that you'll reference later. I'm doing NFS, so I've got to create resources for the filesystems I'll be exporting (the lines that start with cluisterfs), and since I want my exports to be secure, I create a list of clients that will have access to the NFS exports (all others will be blocked). I also create a script that will make changes to SSH and allow me to keep my keys stable over all three machines.
After the resources are declared, we begin the service specification. The IP address is set up, sshd is invoked, samba is started, and the various clusterfs entries are configured. All pretty straightforward here.
Now that we've gone through the configuration file, lets explain some of the underlying implementation. You notice that the configuration invoked the script /etc/init.d/sshd. As you probably know, that is the startup/shutdown script for sshd, which is typically started during the init for multiuser networked runlevels (3 and 5 in RH machines). Since we're starting it now, that would seem to imply that it wasn't running beforehand, however that is not the case. Actually, I had replaced /etc/init.d/sshd with a cluster-aware version that pointed various key files to the clustered filesystems. Here are the changes:
# Begin cluster-ssh modifications
if [ -z "$OCF_RESKEY_service_name" ]; then
#
# Normal / system-wide ssh configuration
#
RSA1_KEY=/etc/ssh/ssh_host_key
RSA_KEY=/etc/ssh/ssh_host_rsa_key
DSA_KEY=/etc/ssh/ssh_host_dsa_key
PID_FILE=/var/run/sshd.pid
else
#
# Per-service ssh configuration
#
RSA1_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_key
RSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_rsa_key
DSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_dsa_key
PID_FILE=/var/run/sshd-$OCF_RESKEY_service_name.pid
CONFIG_FILE="/etc/cluster/ssh/$OCF_RESKEY_service_name/sshd_config"
[ -n "$CONFIG_FILE" ] && OPTIONS="$OPTIONS -f $CONFIG_FILE"
prog="$prog ($OCF_RESKEY_service_name)"
fi
[ -n "$PID_FILE" ] && OPTIONS="$OPTIONS -o PidFile=$PID_FILE"
# End cluster-ssh modifications
I got these changes from this wiki entry, and it seemed to work stably, even if the rest of the cluster didn't always.
You'll also notice that I specify all the things in the services section that normally exist in /etc/exports. That file isn't used in RHCS-clustered NFS. The equivalent of exports is generated on the fly by the cluster system. This implies that you should turn off the NFS daemon and let the cluster manager handle it.
When it comes to Samba, you're going to need to create configurations for the cluster manager to point to, since the configs aren't generated on the fly like NFS. The naming scheme is /etc/samba/smb.conf.SHARENAME, so in the case of Operations above, I used /etc/samba/smb.conf.Operations. I believe that rgmanager (resource group manager) automatically creates a template for you to edit, but be aware that it takes a particular naming scheme.
Assuming you've created cluster aware LVM volumes (you did read the howto I linked to earlier, right?), you'll undoubtedly want to create a filesystem. GFS is the most common filesystem for RHCS, and can be made using 'mkfs.gfs2', but before you start making filesystems willy-nilly, you should know a few things.
First, GFS2 is a journaled filesystem, meaning that data that will be written to disk is written to a scratch pad first (the scratch pad is called a journal), then copied from the scratch pad to the disk, thus if access to the disk is lost while writing to the filesystem, it can be recopied from the journal.
Each node that will have write access to the GFS2 volume needs to have its own scratch pad. If you've got a 3 node cluster, that means you need three journals. If you've got 3 and you're going to be adding 2 more, just make 5 and save yourself a headache. The number of journals can be altered later (using gfs2_jadd), but just do it right the first time.
For more information on creating and managing gfs2, check the Redhat docs.
I should also throw in a note about lock managers here. Computer operating systems today are inherently multitasking. Whenever one program starts to write to a file, a lock is produced which prevents (hopefully) other programs from writing to the same file. To replicate that functionality in a cluster, you use a "lock manager". The old standard was GULM, the Grand Unified Lock Manager. It was replaced by "DLM", the Distributed Lock Manager. If you're reading documentation that openly suggests GULM, you're reading very old documentation and should probably look for something newer.
Once you've got your cluster configured, you probably want to start it. Here's the order I turned things on in:
# starts the cluster manager
service cman start
# starts the clustered LVM daemon
service clvmd start
# mounts the clustered filesystems (after clvmd has been started)
mount -a
# starts the resource manager, which turns on the various services, etc
service rmanager start
I've found that running these in that order will sometimes work and sometimes they'll hang. If it hangs, it's waiting to find other nodes. To remedy that, I try to start the cluster on all nodes at the same time. Also, if you don't the post_join_delay will bite your butt and fence the other nodes.
Have no false assumptions that this will work the first time. Or the second. As you can see, I made it to my 81st configuration before I gave up, and I did a fair bit of research between versions. Make liberal use of your system logs, which will point to reasons that your various cluster daemons are failing, and try to divine the reasons.
Assuming that your cluster is up and running, you can check on the status with clustat. Move the services with clusvcadm, and manuallyfence nodes with fence_manual. Expect to play a lot, and give yourself a lot of time to play and test. Test Test Test. Once your cluster is stable, try to break it. Unplug machines, network cables, and so on, watching logs to see what happens, when, and why. Use all the documentation you can find, but keep in mind that it may be old.
The biggest source of enlightenment (especially to how screwed I was) came from the #linux-cluster channel on IRC. There are mailing lists, as well, and if you're really desperate, drop me a line and I'll try to find you help.
So that's it. A *long* time in the making, without a happy ending, but hopefully I can help someone else. Drop a comment below regaling me with stories of your great successes (or if RHCS drove you to drink, let me know that too!).
Thanks for reading!
Subscribe to:
Posts (Atom)


