After months and months (and months) of asking, FINALLY, my work got me a bookshelf subscription to O'Reilly's Safari Online. If you're unacquainted with this site, click the previous link. It's an online library of IT books from pretty much every major publisher. With my bookshelf subscription, I can "check out" 10 books a month and put them on my "bookshelf", so that they're available to me. With the even cooler "library" subscription, you just go read whatever you want. Your bookshelf doesn't have limits, and it just goes.
Excellent.
A few months ago, I know exactly what I would have checked out first, however I now own the most excellent tome The Practice of Systems and Network Administration. Let me just say that if you don't have it yet, I give it my highest recommendation.
So my question is, what books do you recommend that I get first?
Thursday, April 30, 2009
Wednesday, April 29, 2009
Progressing towards a true backup site
A while back, I moved our production site into a Tier 4 co-location in NJ. Our former primary site became the backup, and things went very smoothly.
Now we're continuing on with our plans of centralizing our company in the northeast of the US. To advance these plans, I'm less than a week away from building a backup site into another tier 4 colo operated by the same company as the primary, but in Philadelphia. This will give us the benefit of being able to lease a fast (100Mb/s) line between the two sites on pre-existing fiber. I cannot tell you how excited I am to be able to have that sort of bandwidth and not rely on T1s.
The most exciting part of this backup site will be that it will use almost exactly the same equipment as the primary site, top to bottom. Back when we were ordering equipment for the primary site, we ordered 2 Dell PowerEdge 1855 enclosures, and we ordered 20 1955s to fill them up. Our SAN storage at the primary is a Dell-branded EMC AX4-5, and we just bought a 2nd for the backup site (though the backup site's storage is only single controller while the primary has redundant controllers. We can always purchase another if we need). We're using the same load balancer as the primary, and we'll have the same Juniper Netscreen firewall configuration. Heck, we're even going to have the same Netgear VPN concentrator. It's going to be a very good thing.
I don't know that I'll have time to create the same sort of diagrams for the rack as I did before, but I should be able to make an adequate spreadsheet of the various pieces of equipment. When all of the pieces are done and in place, I am going to install RackTables to keep track of what is installed where. I mentioned RackTables before on my twitter feed and got some very positive feedback, so if you're looking for a piece of software to keep track of your installed hardware, definitely check that out.
The rest of this week will be spent configuring various network devices. I knocked out the storage array on Monday and two ethernet switches & the fiber switch yesterday. Today I'll be doing the Netscreens, one of the routers (the other will be delivered Friday), and the VPN box. Don't look for extensive updates until next week, when I'll review the install process.
Now we're continuing on with our plans of centralizing our company in the northeast of the US. To advance these plans, I'm less than a week away from building a backup site into another tier 4 colo operated by the same company as the primary, but in Philadelphia. This will give us the benefit of being able to lease a fast (100Mb/s) line between the two sites on pre-existing fiber. I cannot tell you how excited I am to be able to have that sort of bandwidth and not rely on T1s.
The most exciting part of this backup site will be that it will use almost exactly the same equipment as the primary site, top to bottom. Back when we were ordering equipment for the primary site, we ordered 2 Dell PowerEdge 1855 enclosures, and we ordered 20 1955s to fill them up. Our SAN storage at the primary is a Dell-branded EMC AX4-5, and we just bought a 2nd for the backup site (though the backup site's storage is only single controller while the primary has redundant controllers. We can always purchase another if we need). We're using the same load balancer as the primary, and we'll have the same Juniper Netscreen firewall configuration. Heck, we're even going to have the same Netgear VPN concentrator. It's going to be a very good thing.
I don't know that I'll have time to create the same sort of diagrams for the rack as I did before, but I should be able to make an adequate spreadsheet of the various pieces of equipment. When all of the pieces are done and in place, I am going to install RackTables to keep track of what is installed where. I mentioned RackTables before on my twitter feed and got some very positive feedback, so if you're looking for a piece of software to keep track of your installed hardware, definitely check that out.
The rest of this week will be spent configuring various network devices. I knocked out the storage array on Monday and two ethernet switches & the fiber switch yesterday. Today I'll be doing the Netscreens, one of the routers (the other will be delivered Friday), and the VPN box. Don't look for extensive updates until next week, when I'll review the install process.
Sunday, April 26, 2009
The Goodwill Computer Store in Houston, TX
I've been to several Goodwill stores, bothing donating and shopping, and I always see an odd array of old used computer parts. It's a walk down memory lane, usually. I never dreamed that there would be a Goodwill store entirely devoted to computers. Take a look at some of the pictures there. It's unbelievable. I'd love to go there and just walk through. Definitely an old-computer-geek's dream.
Wednesday, April 22, 2009
APC Data Center University
If you're hankering for some free learning and you have any interest at all in data centers, check out the free Data Center University by APC. I registered, but haven't "attended" my first class yet. I'll check it out when I get a little more time, but I just thought some of you might like to know about this, if you didn't already.
Discussion on /. - Should cables be replaced?
Yesterday there was a pretty good discussion going on over at Slashdot regarding changing out network cables. I thought some of you might be interested in it. Sorry for the tardiness, but better late than never, I suppose.
Another thread to add to my SlashDocs bookmarks!
Another thread to add to my SlashDocs bookmarks!
Tuesday, April 21, 2009
My trouble with bonded interfaces
In an effort to improve the redundancy of our network, I have all of our blade servers configured to have bonded network interfaces. Bonding the interfaces in linux means that eth0 and eth1 form together like Voltron into bond0, an interface that can be "high availability", meaning if one physical port (or the device it is plugged into) dies, the other can take over.
Because I wanted to eliminate a single point of failure, I used two switches:
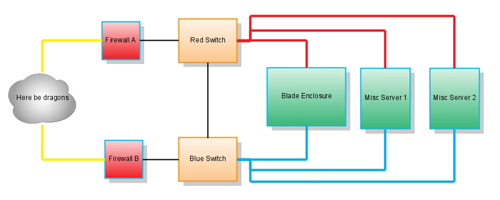
The switches are tied together to make sure traffic on one switch hits the other if necessary.
Here is my problem, though: I have had an array of interesting traffic patterns from my hosts. Some times they'll have occasional intermittent loss of connectivity, sometimes they'll have regular time periods of non-connectivity (both of which I've solved by changing the bonding method), and most recently, I've had the very irritating problem of a host connecting perfectly fine to anything on the local subnet, but remote traffic experiences heavy traffic loss. To fix the problem, all I have to do is unplug one of the network cables.
I've got the machine set up in bonding mode 0. According to the documents, mode 0 is:
It would be at least logical if I lost 50% of the packets. Two interfaces, one malfunctioning, half the packets. But no, it's more like 70% of the packets getting lost, and I haven't managed to figure it out yet.
If you check my twitter feed for yesterday, I was whining about forgetting a jacket. This is because I was hanging out in the colocation running tests. 'tcpdump' shows that the packets are actually being sent. Only occasional responses are received, though, unless the other host is local, in which case everything is fine.
There are several hosts configured identically to this one, however this is the only one displaying this issue. Normally I'd suspect the firewall, but there isn't anything in the configuration that would single out this machine, and the arp tables check out everywhere. I'm confused, but I haven't given up yet. I'll let you know if I figure it out, and in the mean time, if you've got suggestions, I'm open to them.
Because I wanted to eliminate a single point of failure, I used two switches:
The switches are tied together to make sure traffic on one switch hits the other if necessary.
Here is my problem, though: I have had an array of interesting traffic patterns from my hosts. Some times they'll have occasional intermittent loss of connectivity, sometimes they'll have regular time periods of non-connectivity (both of which I've solved by changing the bonding method), and most recently, I've had the very irritating problem of a host connecting perfectly fine to anything on the local subnet, but remote traffic experiences heavy traffic loss. To fix the problem, all I have to do is unplug one of the network cables.
I've got the machine set up in bonding mode 0. According to the documents, mode 0 is:
Round-robin policy: Transmit packets in sequential
order from the first available slave through the
last. This mode provides load balancing and fault
tolerance.
It would be at least logical if I lost 50% of the packets. Two interfaces, one malfunctioning, half the packets. But no, it's more like 70% of the packets getting lost, and I haven't managed to figure it out yet.
If you check my twitter feed for yesterday, I was whining about forgetting a jacket. This is because I was hanging out in the colocation running tests. 'tcpdump' shows that the packets are actually being sent. Only occasional responses are received, though, unless the other host is local, in which case everything is fine.
There are several hosts configured identically to this one, however this is the only one displaying this issue. Normally I'd suspect the firewall, but there isn't anything in the configuration that would single out this machine, and the arp tables check out everywhere. I'm confused, but I haven't given up yet. I'll let you know if I figure it out, and in the mean time, if you've got suggestions, I'm open to them.
Monday, April 20, 2009
Sysadmin Aphorisms
I ran across this great list of Sysadmin Aphorisms. Give it a quick read through, as there are (I think) some thought provoking statements.
What would you add?
What would you add?
I see in my future...
Fixing recurring problems, working on new storage implementation, and ordering/configuration of new networking gear.
I'm getting ready to build out our "beta" site, as in, secondary, behind the currently-live "alpha" site. The 10 blades are mostly configured (and since they take 208v electricity, they're as configured as they're going to get until the rack gets turned up). I've got the AX4-5 to partition as well. I remember the procedure pretty well from the alpha config. We were very lucky to be able to get the same piece of kit for both sites. We had been looking at AoE and iSCSI, but CDW sold us the AX4-5 for considerably less than Dell was asking. And the front bezel is prettier to boot.
I'm also going to need to pick up a couple of Ciscos. Since my networking needs are light, I prefer to get refurbished routers. I'll be needing two fast ethernet ports, to 2621's will be perfect.
The recurring problem is sort of interesting. Every once in a while, the host will stop responding to packets. My kneejerk response was 'bad network cable', but the machine has two bonded interfaces. One bad cable wouldn't cause that, and nothing else on the switch is experiencing the same symptoms. I'm going to head into the colocation to try and figure out what's going on. If the resolution is at all unique, I'll post about it here.
I'm getting ready to build out our "beta" site, as in, secondary, behind the currently-live "alpha" site. The 10 blades are mostly configured (and since they take 208v electricity, they're as configured as they're going to get until the rack gets turned up). I've got the AX4-5 to partition as well. I remember the procedure pretty well from the alpha config. We were very lucky to be able to get the same piece of kit for both sites. We had been looking at AoE and iSCSI, but CDW sold us the AX4-5 for considerably less than Dell was asking. And the front bezel is prettier to boot.
I'm also going to need to pick up a couple of Ciscos. Since my networking needs are light, I prefer to get refurbished routers. I'll be needing two fast ethernet ports, to 2621's will be perfect.
The recurring problem is sort of interesting. Every once in a while, the host will stop responding to packets. My kneejerk response was 'bad network cable', but the machine has two bonded interfaces. One bad cable wouldn't cause that, and nothing else on the switch is experiencing the same symptoms. I'm going to head into the colocation to try and figure out what's going on. If the resolution is at all unique, I'll post about it here.
Thursday, April 16, 2009
And you thought the fan was bad...
The other day, I posted some photos of a fan hanging from the rafters. Those pictures have nothing on these:
Parks Hall Server Room Fire. This happened in July of 2002 and was apparently caused by an electrical problem in one of the old servers. Here is a news article on it.
I just don't have words that would express my disbelief. wow.
If there is any bright side, the staff at UWW produced an in-depth paper on the disaster recovery and rebuilding process. It's a good read, and a very sobering thought that something like this could easily happen to any of us.
If you ever wanted an argument for off-site backups, there you go.
Parks Hall Server Room Fire. This happened in July of 2002 and was apparently caused by an electrical problem in one of the old servers. Here is a news article on it.
I just don't have words that would express my disbelief. wow.
If there is any bright side, the staff at UWW produced an in-depth paper on the disaster recovery and rebuilding process. It's a good read, and a very sobering thought that something like this could easily happen to any of us.
If you ever wanted an argument for off-site backups, there you go.
Wednesday, April 15, 2009
Future (or current?) replacement for Nagios?
I was unaware of this project, but thanks to stephenpc on twitter, I read an excellent (if a bit dated) article on RootDev which brought OpenNMS to my attention as a possible replacement for nagios.
I was mildly surprised, mostly because I haven't been shopping for a Nagios replacement since I installed and configured Nagios 3. I had looked at Zenoss as a possibility, but decided to stick with Nagios since I was already familiar with the configuration routine (and 3.x had some great improvements in that regard).
Judging by Craig's comments in that article, openNMS solves problems that I don't have, like so many hosts or services that you can't get to the bottom of the summary page without it refreshing. That's a problem I'm glad I don't have, but I know that some of you run very large networks. So my question would be, what do you large-network guys use for monitoring? And if you have a small network, do you use monitoring? I remember back to the time before I knew about monitoring solutions like Nagios, and it scares me to death. I would actually manually check on important services to make sure they were up, and that was my only way of doing it.
Of course, in my defense I was young and naive then, and didn't even backup things to tape. Ah, the folly of youth.
I was mildly surprised, mostly because I haven't been shopping for a Nagios replacement since I installed and configured Nagios 3. I had looked at Zenoss as a possibility, but decided to stick with Nagios since I was already familiar with the configuration routine (and 3.x had some great improvements in that regard).
Judging by Craig's comments in that article, openNMS solves problems that I don't have, like so many hosts or services that you can't get to the bottom of the summary page without it refreshing. That's a problem I'm glad I don't have, but I know that some of you run very large networks. So my question would be, what do you large-network guys use for monitoring? And if you have a small network, do you use monitoring? I remember back to the time before I knew about monitoring solutions like Nagios, and it scares me to death. I would actually manually check on important services to make sure they were up, and that was my only way of doing it.
Of course, in my defense I was young and naive then, and didn't even backup things to tape. Ah, the folly of youth.
The lord answers prayers
And apparently so does docwhat.
Since I began to get really proficient at vi(m), I started to wish that Netscape (then Mozilla (and now Firefox) ) had a plugin for vi-style editing of text boxes. Oh, how I searched and searched.
Today, I found something nearly as good. Better in a lot of ways, really. It's called It's All Text!, a firefox extension that allows you to launch your favorite editor to populate a textbox. Just save the document that you're typing, and voila! The text goes into the box.
I used gvim to type this entire blog entry. If I can figure out a way to get it to launch automatically whenever I click in a text box, I might be able to die a happy man.
Since I began to get really proficient at vi(m), I started to wish that Netscape (then Mozilla (and now Firefox) ) had a plugin for vi-style editing of text boxes. Oh, how I searched and searched.
Today, I found something nearly as good. Better in a lot of ways, really. It's called It's All Text!, a firefox extension that allows you to launch your favorite editor to populate a textbox. Just save the document that you're typing, and voila! The text goes into the box.
I used gvim to type this entire blog entry. If I can figure out a way to get it to launch automatically whenever I click in a text box, I might be able to die a happy man.
Tuesday, April 14, 2009
Testing Disk Speed
If you've got network storage, whether NAS or SAN, you probably care how fast it is.
There are a lot of ways to increase speed, such as choosing the right RAID level, making sure you have the right spindle count. (Incidentally, I found a very interesting, if somewhat lacking, RAID estimator that is fun to play with. I just wish they supported more RAID levels...)
Anyway, you want to design your storage to go fast. But how do you test it? Josh Berkus suggests using 'dd' in Unix to test the speed of the writes and reads from disk.
I've used this technique, but without the additional step of clearing the memory cache by writing a file as large as the machine's memory. I don't know if it's guaranteed to work in all cases, but it's a good idea to account for that.
Anyone else have a better more "official" way to calculate read/write speeds?
[UPDATE]
As non4top mentioned in the comments, bonnie++ is a well known program for viewing speed. Funnily enough, it was written by Russell Coker, who has a blog that I read quite often. Iozone also seems to be pretty popular according to Dave, and I can see why from those graphs :-)
If you're interested, here's a longer list of drive benchmark software.
There are a lot of ways to increase speed, such as choosing the right RAID level, making sure you have the right spindle count. (Incidentally, I found a very interesting, if somewhat lacking, RAID estimator that is fun to play with. I just wish they supported more RAID levels...)
Anyway, you want to design your storage to go fast. But how do you test it? Josh Berkus suggests using 'dd' in Unix to test the speed of the writes and reads from disk.
I've used this technique, but without the additional step of clearing the memory cache by writing a file as large as the machine's memory. I don't know if it's guaranteed to work in all cases, but it's a good idea to account for that.
Anyone else have a better more "official" way to calculate read/write speeds?
[UPDATE]
As non4top mentioned in the comments, bonnie++ is a well known program for viewing speed. Funnily enough, it was written by Russell Coker, who has a blog that I read quite often. Iozone also seems to be pretty popular according to Dave, and I can see why from those graphs :-)
If you're interested, here's a longer list of drive benchmark software.
Monday, April 13, 2009
HOWTO: RedHat Cluster Suite
Alright, here it is, my writeup on RHCS. Before I continue, I need to remind you that, as I mentioned before, I had to pull the plug on it. I never got it working reliably so that a failure wouldn't bring down the entire cluster, and from the comments in that thread, I'm not alone.
This documentation is provided for working with the RedHat Cluster Suite that shipped with RHEL/CentOS 5.2. It is important to keep this in mind, because if you are working with a newer version, there may be major changes. This has already happened before with the 4.x-5.x switch, rendering most of the documentation on the internet deprecated at best, and destructive at worst. The single most helpful document I found was this: The Red Hat Cluster Suite NFS Cookbook, and even with that, you will notice the giant "Draft Copy" watermark. I haven't found anything to suggest that it was ever revised past "draft" form.
In my opinion, RedHat Cluster Suite is not ready for "prime time", and even in the words of a developer from #linux-cluster, "I don't know if I would use 5.2 stock release with production data". That being said, you might be interested in playing around with it, or you might choose to ignore my warnings and try it on production systems. If it's the latter, please do yourself a favor and have a backup plan. I know from experience that it's no fun to rip out a cluster configuration and try to set up discrete fileservers.
Alright, that's enough of a warning I think. Lets overview what RHCS does.
RedHat Cluster Suite is designed to allow High Availability (HA) services, as opposed to a compute cluster which gives you the benefit of parallel processing. If you're rendering movies, you want a compute cluster. If you want to make sure that your fileserver is always available, you want an HA cluster.
The general idea of RHCS is that you have a number of servers (nodes), hopefully at least 3, but 2 is possible but not recommended. Each of those machines is configured identically and has the cluster configuration distributed to it. The "cluster manager" (cman) keeps track of who all is a member of the cluster. The Cluster Configuration System (ccs) makes sure that all cluster nodes have the same configuration. The resource manager (rgmanager) makes sure that your configured resources are available on each node, the Clustered Logical Volume Manager (clvmd) makes sure that everyone agrees that disks are available to the cluster, and the lock manager (dlm (distributed lock manager) or gulm (grand unified lock manager (deprecated))) ensures that your filesystems' integrity is maintained across the cluster. Sounds simple, right? Right.
Alright, so lets make sure the suite is installed. Easiest way is to make sure the Clustering and Cluster Storage options are selected at install or in system-config-packages. Note: if you have a standard RedHat Enterprise license, you'll need to pony up over a thousand dollars more per year per node to get the clustering options. The benefit of this is that you get support from Redhat, the value of which I have heard questioned by several people. Or you could just install CentOS, which is a RHEL-clone. I can't recommend Fedora, just because Redhat seems to test things out there as opposed to RHEL (and CentOS) which only gets "proven" software. Unless you're talking about perl, but I digress.
So the software is installed, terrific. Lets discuss your goals now. It is possible, though not very useful, to have a cluster configured without any resources. Typically you will want at least one shared IP address. In this case, the active node will have the IP, and whenever the active node changes, the IP will move with it. This is as good a time as any to mention that you won't be able to see this IP when you run 'ifconfig'. You've got to find it with 'ip addr list'.
Aside from a common IP address, you'll probably want to have a shared filesystem. Depending on what other services your cluster will be providing, it might be possible to get away with having them all mount a remote NFS share. You'll have to determine whether your service will work reliably over NFS on your own. Here's a hint: vmware server won't, because of the way NFS locks files (At least I haven't gotten it to work since I last tried a few months ago. YMMV).
Regardless, we'll assume you're not able to use NFS, and you've got to have a shared disk. This is accomplished by using a Storage Area Network (SAN), most commonly. Setting up and configuring your SAN is beyond the scope of this entry, but the key point is that all of your cluster nodes have to have equal access to the storage resources. Once you've assigned that access in the storage configuration, make sure that each machine can see the volumes that it is supposed to have access to.
After you've verified that all the volumes can be accessed by all of the servers, filesystems must be created. I cannot recommend LVM highly enough. I created an introduction to LVM a last year to help understand the concept and why you want to use it. Use this knowledge and the LVM Howto to create your logical volumes. Alternately, system-config-lvm is a viable gui alternative, although the interface takes some getting used to. When creating volume groups, make sure that the clustered flag is set to yes. This will stop them from showing up when the node isn't connected to the cluster, such as right after booting up.
To make sure that the lock manager can deal with the filesystems, on all hosts, you must also edit the LVM configuration (typically /etc/lvm/lvm.conf) to change "locking_type = 1" to "locking_type = 3", which tells LVM to use clustered locking. Restart LVM processes with 'service lvm2-monitor restart'.
Now, lets talk about the actual configuration file. cluster.conf is an XML file that's separated by tags into sections. Each of these sections is housed under the "cluster" tag.
Here is the content of my file, as an example:
If you read carefully, most of the entries can be self explained, but we'll go over the broad strokes.
The first line names the cluster. It also has a "config_version" property. This config_version value is used to decide which cluster node has the most up-to-date configuration. In addition, if you edit the file and try to redistribute it without incrementing the value, you'll get an error, because the config_versions are the same but the contents are different. Always remember to increment the config_version.
The next line is a single entry (you can tell from the trailing /) which defines the fence daemon. Fencing in a cluster is a means to disable a machine from accessing cluster resources. The reason behind this is that if a node goes rogue, detaches itself from the other cluster members, and unilaterally decides that it is going to have read-write access to the data, then the data will end up corrupt. The actual cluster master will be writing to the data at the same time the rogue node will, and that is a Very Bad Thing(tm). To prevent this, all nodes are setup so that they are able to "fence" other nodes that disconnect from the group. The post fail delay in my config means "wait 30 seconds before killing a node". How to do this is going to be talked about later in the fencedevices section.
The post_join_delay is misnamed and should really be called post_create_delay, since the only time it is used is when the cluster is started (as in, there is no running node, and the first machine is turned on). The default action of RHCS is to wait 6 seconds after being started, and to "fence" any nodes listed in the configuration who haven't connected yet. I've increased this value to 30 seconds. The best solution is to never start the cluster automatically after booting. This allows you to manually startup cluster services, which can prevent unnecessary fencing of machines.
Fencing is by far what gave me the most problem.
The next section is clusternodes. This section defines each of the nodes that will be connecting to this cluster. The name will be what you refer to the nodes by using the command line tools, the node ID will be used in the logs and internal referencing, and "votes" has to do with an idea called "quorum". The quorum is the number of nodes necessary to operate a cluster. Typically it's more than 50% of the total number of nodes. In a three-node cluster, it's 2. This is the reason that two node clusters are tricky: by dictating a quorum of 1, you are telling rogue cluster nodes that they should assume they are the active node. Not good. If you find yourself in the unenviable position of only having 2 possible nodes, you need to use a quorum disk.
Inside each cluster node declaration, you need to specify a fence device. The fence device is the method used by fenced (the fencing daemon) to turn off the remote node. Explaining the various methods is beyond this document, but read the fencing documentation for details, and hope not much has changed in the software since they wrote the docs.
After clusternodes, the cman (cluster manager) line dictates the quorum (called "expected_votes") and two_node="0", which means "this isn't a two node cluster".
The next section is the fencedevices declaration. Since I was using dell poweredge blades, I used the fence_drac agent, which has DRAC specific programming to turn off nodes. Check the above-linked-documentation for your solution.
<rm> stands for Resource Manager, and is where we will declare which resources exist, and where they will be assigned and deployed.
failoverdomains are the list of various groups of cluster nodes. These should be created based on the services that your clusters will share. Since I was only clustering my three file servers, I only had one failover domain. If I wanted to cluster my web servers, I would have created a 2nd failover domain (in addition to creating the nodes in the upper portion of the file, as well). You'll see below in the services section where the failoverdomain comes into effect.
In the resources list, you create "shortcuts" to things that you'll reference later. I'm doing NFS, so I've got to create resources for the filesystems I'll be exporting (the lines that start with cluisterfs), and since I want my exports to be secure, I create a list of clients that will have access to the NFS exports (all others will be blocked). I also create a script that will make changes to SSH and allow me to keep my keys stable over all three machines.
After the resources are declared, we begin the service specification. The IP address is set up, sshd is invoked, samba is started, and the various clusterfs entries are configured. All pretty straightforward here.
Now that we've gone through the configuration file, lets explain some of the underlying implementation. You notice that the configuration invoked the script /etc/init.d/sshd. As you probably know, that is the startup/shutdown script for sshd, which is typically started during the init for multiuser networked runlevels (3 and 5 in RH machines). Since we're starting it now, that would seem to imply that it wasn't running beforehand, however that is not the case. Actually, I had replaced /etc/init.d/sshd with a cluster-aware version that pointed various key files to the clustered filesystems. Here are the changes:
# Begin cluster-ssh modifications
if [ -z "$OCF_RESKEY_service_name" ]; then
#
# Normal / system-wide ssh configuration
#
RSA1_KEY=/etc/ssh/ssh_host_key
RSA_KEY=/etc/ssh/ssh_host_rsa_key
DSA_KEY=/etc/ssh/ssh_host_dsa_key
PID_FILE=/var/run/sshd.pid
else
#
# Per-service ssh configuration
#
RSA1_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_key
RSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_rsa_key
DSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_dsa_key
PID_FILE=/var/run/sshd-$OCF_RESKEY_service_name.pid
CONFIG_FILE="/etc/cluster/ssh/$OCF_RESKEY_service_name/sshd_config"
[ -n "$CONFIG_FILE" ] && OPTIONS="$OPTIONS -f $CONFIG_FILE"
prog="$prog ($OCF_RESKEY_service_name)"
fi
[ -n "$PID_FILE" ] && OPTIONS="$OPTIONS -o PidFile=$PID_FILE"
# End cluster-ssh modifications
I got these changes from this wiki entry, and it seemed to work stably, even if the rest of the cluster didn't always.
You'll also notice that I specify all the things in the services section that normally exist in /etc/exports. That file isn't used in RHCS-clustered NFS. The equivalent of exports is generated on the fly by the cluster system. This implies that you should turn off the NFS daemon and let the cluster manager handle it.
When it comes to Samba, you're going to need to create configurations for the cluster manager to point to, since the configs aren't generated on the fly like NFS. The naming scheme is /etc/samba/smb.conf.SHARENAME, so in the case of Operations above, I used /etc/samba/smb.conf.Operations. I believe that rgmanager (resource group manager) automatically creates a template for you to edit, but be aware that it takes a particular naming scheme.
Assuming you've created cluster aware LVM volumes (you did read the howto I linked to earlier, right?), you'll undoubtedly want to create a filesystem. GFS is the most common filesystem for RHCS, and can be made using 'mkfs.gfs2', but before you start making filesystems willy-nilly, you should know a few things.
First, GFS2 is a journaled filesystem, meaning that data that will be written to disk is written to a scratch pad first (the scratch pad is called a journal), then copied from the scratch pad to the disk, thus if access to the disk is lost while writing to the filesystem, it can be recopied from the journal.
Each node that will have write access to the GFS2 volume needs to have its own scratch pad. If you've got a 3 node cluster, that means you need three journals. If you've got 3 and you're going to be adding 2 more, just make 5 and save yourself a headache. The number of journals can be altered later (using gfs2_jadd), but just do it right the first time.
For more information on creating and managing gfs2, check the Redhat docs.
I should also throw in a note about lock managers here. Computer operating systems today are inherently multitasking. Whenever one program starts to write to a file, a lock is produced which prevents (hopefully) other programs from writing to the same file. To replicate that functionality in a cluster, you use a "lock manager". The old standard was GULM, the Grand Unified Lock Manager. It was replaced by "DLM", the Distributed Lock Manager. If you're reading documentation that openly suggests GULM, you're reading very old documentation and should probably look for something newer.
Once you've got your cluster configured, you probably want to start it. Here's the order I turned things on in:
# starts the cluster manager
service cman start
# starts the clustered LVM daemon
service clvmd start
# mounts the clustered filesystems (after clvmd has been started)
mount -a
# starts the resource manager, which turns on the various services, etc
service rmanager start
I've found that running these in that order will sometimes work and sometimes they'll hang. If it hangs, it's waiting to find other nodes. To remedy that, I try to start the cluster on all nodes at the same time. Also, if you don't the post_join_delay will bite your butt and fence the other nodes.
Have no false assumptions that this will work the first time. Or the second. As you can see, I made it to my 81st configuration before I gave up, and I did a fair bit of research between versions. Make liberal use of your system logs, which will point to reasons that your various cluster daemons are failing, and try to divine the reasons.
Assuming that your cluster is up and running, you can check on the status with clustat. Move the services with clusvcadm, and manuallyfence nodes with fence_manual. Expect to play a lot, and give yourself a lot of time to play and test. Test Test Test. Once your cluster is stable, try to break it. Unplug machines, network cables, and so on, watching logs to see what happens, when, and why. Use all the documentation you can find, but keep in mind that it may be old.
The biggest source of enlightenment (especially to how screwed I was) came from the #linux-cluster channel on IRC. There are mailing lists, as well, and if you're really desperate, drop me a line and I'll try to find you help.
So that's it. A *long* time in the making, without a happy ending, but hopefully I can help someone else. Drop a comment below regaling me with stories of your great successes (or if RHCS drove you to drink, let me know that too!).
Thanks for reading!
This documentation is provided for working with the RedHat Cluster Suite that shipped with RHEL/CentOS 5.2. It is important to keep this in mind, because if you are working with a newer version, there may be major changes. This has already happened before with the 4.x-5.x switch, rendering most of the documentation on the internet deprecated at best, and destructive at worst. The single most helpful document I found was this: The Red Hat Cluster Suite NFS Cookbook, and even with that, you will notice the giant "Draft Copy" watermark. I haven't found anything to suggest that it was ever revised past "draft" form.
In my opinion, RedHat Cluster Suite is not ready for "prime time", and even in the words of a developer from #linux-cluster, "I don't know if I would use 5.2 stock release with production data". That being said, you might be interested in playing around with it, or you might choose to ignore my warnings and try it on production systems. If it's the latter, please do yourself a favor and have a backup plan. I know from experience that it's no fun to rip out a cluster configuration and try to set up discrete fileservers.
Alright, that's enough of a warning I think. Lets overview what RHCS does.
RedHat Cluster Suite is designed to allow High Availability (HA) services, as opposed to a compute cluster which gives you the benefit of parallel processing. If you're rendering movies, you want a compute cluster. If you want to make sure that your fileserver is always available, you want an HA cluster.
The general idea of RHCS is that you have a number of servers (nodes), hopefully at least 3, but 2 is possible but not recommended. Each of those machines is configured identically and has the cluster configuration distributed to it. The "cluster manager" (cman) keeps track of who all is a member of the cluster. The Cluster Configuration System (ccs) makes sure that all cluster nodes have the same configuration. The resource manager (rgmanager) makes sure that your configured resources are available on each node, the Clustered Logical Volume Manager (clvmd) makes sure that everyone agrees that disks are available to the cluster, and the lock manager (dlm (distributed lock manager) or gulm (grand unified lock manager (deprecated))) ensures that your filesystems' integrity is maintained across the cluster. Sounds simple, right? Right.
Alright, so lets make sure the suite is installed. Easiest way is to make sure the Clustering and Cluster Storage options are selected at install or in system-config-packages. Note: if you have a standard RedHat Enterprise license, you'll need to pony up over a thousand dollars more per year per node to get the clustering options. The benefit of this is that you get support from Redhat, the value of which I have heard questioned by several people. Or you could just install CentOS, which is a RHEL-clone. I can't recommend Fedora, just because Redhat seems to test things out there as opposed to RHEL (and CentOS) which only gets "proven" software. Unless you're talking about perl, but I digress.
So the software is installed, terrific. Lets discuss your goals now. It is possible, though not very useful, to have a cluster configured without any resources. Typically you will want at least one shared IP address. In this case, the active node will have the IP, and whenever the active node changes, the IP will move with it. This is as good a time as any to mention that you won't be able to see this IP when you run 'ifconfig'. You've got to find it with 'ip addr list'.
Aside from a common IP address, you'll probably want to have a shared filesystem. Depending on what other services your cluster will be providing, it might be possible to get away with having them all mount a remote NFS share. You'll have to determine whether your service will work reliably over NFS on your own. Here's a hint: vmware server won't, because of the way NFS locks files (At least I haven't gotten it to work since I last tried a few months ago. YMMV).
Regardless, we'll assume you're not able to use NFS, and you've got to have a shared disk. This is accomplished by using a Storage Area Network (SAN), most commonly. Setting up and configuring your SAN is beyond the scope of this entry, but the key point is that all of your cluster nodes have to have equal access to the storage resources. Once you've assigned that access in the storage configuration, make sure that each machine can see the volumes that it is supposed to have access to.
After you've verified that all the volumes can be accessed by all of the servers, filesystems must be created. I cannot recommend LVM highly enough. I created an introduction to LVM a last year to help understand the concept and why you want to use it. Use this knowledge and the LVM Howto to create your logical volumes. Alternately, system-config-lvm is a viable gui alternative, although the interface takes some getting used to. When creating volume groups, make sure that the clustered flag is set to yes. This will stop them from showing up when the node isn't connected to the cluster, such as right after booting up.
To make sure that the lock manager can deal with the filesystems, on all hosts, you must also edit the LVM configuration (typically /etc/lvm/lvm.conf) to change "locking_type = 1" to "locking_type = 3", which tells LVM to use clustered locking. Restart LVM processes with 'service lvm2-monitor restart'.
Now, lets talk about the actual configuration file. cluster.conf is an XML file that's separated by tags into sections. Each of these sections is housed under the "cluster" tag.
Here is the content of my file, as an example:
<cluster alias="alpha-fs" config_version="81" name="alpha-fs">
<fence_daemon clean_start="1" post_fail_delay="30" post_join_delay="30"/>
<clusternodes>
<clusternode name="fs1.int.dom" nodeid="1" votes="1">
<fence>
<method name="1">
<device modulename="Server-2" name="blade-enclosure"/>
</method>
</fence>
</clusternode>
<clusternode name="fs2.int.dom" nodeid="2" votes="1">
<fence>
<method name="1">
<device modulename="Server-3" name="blade-enclosure"/>
</method>
</fence>
</clusternode>
<clusternode name="fs3.int.dom" nodeid="3" votes="1">
<fence>
<method name="1">
<device modulename="Server-6" name="blade-enclosure"/>
</method>
</fence>
</clusternode>
</clusternodes>
<cman expected_votes="3" two_node="0"/>
<fencedevices>
<fencedevice agent="fence_drac" ipaddr="10.x.x.4" login="root" name="blade-enclosure" passwd="XXXXX"/>
</fencedevices>
<rm>
<failoverdomains>
<failoverdomain name="alpha-fail1">
<failoverdomainnode name="fs1.int.dom" priority="1"/>
<failoverdomainnode name="fs2.int.dom" priority="2"/>
<failoverdomainnode name="fs3.int.dom" priority="3"/>
</failoverdomain>
</failoverdomains>
<resources>
<clusterfs device="/dev/vgDeploy/lvDeploy" force_unmount="0" fsid="55712" fstype="gfs" mountpoint="/mnt/deploy" name="deployFS"/>
<nfsclient name="app1" options="ro" target="10.x.x.26"/>
<nfsclient name="app2" options="ro" target="10.x.x.27"/>
<clusterfs device="/dev/vgOperations/lvOperations" force_unmount="0" fsid="5989" fstype="gfs" mountpoint="/mnt/operations" name="operationsFS" options=""/>
<clusterfs device="/dev/vgWebsite/lvWebsite" force_unmount="0" fsid="62783" fstype="gfs" mountpoint="/mnt/website" name="websiteFS" options=""/>
<clusterfs device="/dev/vgUsr2/lvUsr2" force_unmount="0" fsid="46230" fstype="gfs" mountpoint="/mnt/usr2" name="usr2FS" options=""/>
<clusterfs device="/dev/vgData/lvData" force_unmount="0" fsid="52227" fstype="gfs" mountpoint="/mnt/data" name="dataFS" options=""/>
<nfsclient name="ops1" options="rw" target="10.x.x.28"/>
<nfsclient name="ops2" options="rw" target="10.x.x.29"/>
<nfsclient name="ops3" options="rw" target="10.x.x.30"/>
<nfsclient name="preview" options="rw" target="10.x.x.42"/>
<nfsclient name="ftp1" options="rw" target="10.x.x.32"/>
<nfsclient name="ftp2" options="rw" target="10.x.x.33"/>
<nfsclient name="sys1" option="rw" target="10.x.x.31"/>
<script name="sshd" file="/etc/init.d/sshd"/>
</resources>
<service autostart="1" domain="alpha-fail1" name="nfssvc">
<ip address="10.x.x.50" monitor_link="1"/>
<script ref="sshd"/>
<smb name="Operations" workgroup="int.dom"/>
<clusterfs ref="deployFS">
<nfsexport name="deploy">
<nfsclient ref="app1"/>
<nfsclient ref="app2"/>
</nfsexport>
</clusterfs>
<clusterfs ref="operationsFS">
<nfsexport name="operations">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
</nfsexport>
</clusterfs>
<clusterfs ref="websiteFS">
<nfsexport name="website">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
<nfsclient ref="preview"/>
</nfsexport>
</clusterfs>
<clusterfs ref="usr2FS">
<nfsexport name="usr2">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
</nfsexport>
</clusterfs>
<clusterfs ref="dataFS">
<nfsexport name="data">
<nfsclient ref="ops1"/>
<nfsclient ref="ops2"/>
<nfsclient ref="ops3"/>
<nfsclient ref="ftp1"/>
<nfsclient ref="ftp2"/>
<nfsclient ref="sys1"/>
</nfsexport>
</clusterfs>
</service>
</rm>
</cluster>
If you read carefully, most of the entries can be self explained, but we'll go over the broad strokes.
The first line names the cluster. It also has a "config_version" property. This config_version value is used to decide which cluster node has the most up-to-date configuration. In addition, if you edit the file and try to redistribute it without incrementing the value, you'll get an error, because the config_versions are the same but the contents are different. Always remember to increment the config_version.
The next line is a single entry (you can tell from the trailing /) which defines the fence daemon. Fencing in a cluster is a means to disable a machine from accessing cluster resources. The reason behind this is that if a node goes rogue, detaches itself from the other cluster members, and unilaterally decides that it is going to have read-write access to the data, then the data will end up corrupt. The actual cluster master will be writing to the data at the same time the rogue node will, and that is a Very Bad Thing(tm). To prevent this, all nodes are setup so that they are able to "fence" other nodes that disconnect from the group. The post fail delay in my config means "wait 30 seconds before killing a node". How to do this is going to be talked about later in the fencedevices section.
The post_join_delay is misnamed and should really be called post_create_delay, since the only time it is used is when the cluster is started (as in, there is no running node, and the first machine is turned on). The default action of RHCS is to wait 6 seconds after being started, and to "fence" any nodes listed in the configuration who haven't connected yet. I've increased this value to 30 seconds. The best solution is to never start the cluster automatically after booting. This allows you to manually startup cluster services, which can prevent unnecessary fencing of machines.
Fencing is by far what gave me the most problem.
The next section is clusternodes. This section defines each of the nodes that will be connecting to this cluster. The name will be what you refer to the nodes by using the command line tools, the node ID will be used in the logs and internal referencing, and "votes" has to do with an idea called "quorum". The quorum is the number of nodes necessary to operate a cluster. Typically it's more than 50% of the total number of nodes. In a three-node cluster, it's 2. This is the reason that two node clusters are tricky: by dictating a quorum of 1, you are telling rogue cluster nodes that they should assume they are the active node. Not good. If you find yourself in the unenviable position of only having 2 possible nodes, you need to use a quorum disk.
Inside each cluster node declaration, you need to specify a fence device. The fence device is the method used by fenced (the fencing daemon) to turn off the remote node. Explaining the various methods is beyond this document, but read the fencing documentation for details, and hope not much has changed in the software since they wrote the docs.
After clusternodes, the cman (cluster manager) line dictates the quorum (called "expected_votes") and two_node="0", which means "this isn't a two node cluster".
The next section is the fencedevices declaration. Since I was using dell poweredge blades, I used the fence_drac agent, which has DRAC specific programming to turn off nodes. Check the above-linked-documentation for your solution.
<rm> stands for Resource Manager, and is where we will declare which resources exist, and where they will be assigned and deployed.
failoverdomains are the list of various groups of cluster nodes. These should be created based on the services that your clusters will share. Since I was only clustering my three file servers, I only had one failover domain. If I wanted to cluster my web servers, I would have created a 2nd failover domain (in addition to creating the nodes in the upper portion of the file, as well). You'll see below in the services section where the failoverdomain comes into effect.
In the resources list, you create "shortcuts" to things that you'll reference later. I'm doing NFS, so I've got to create resources for the filesystems I'll be exporting (the lines that start with cluisterfs), and since I want my exports to be secure, I create a list of clients that will have access to the NFS exports (all others will be blocked). I also create a script that will make changes to SSH and allow me to keep my keys stable over all three machines.
After the resources are declared, we begin the service specification. The IP address is set up, sshd is invoked, samba is started, and the various clusterfs entries are configured. All pretty straightforward here.
Now that we've gone through the configuration file, lets explain some of the underlying implementation. You notice that the configuration invoked the script /etc/init.d/sshd. As you probably know, that is the startup/shutdown script for sshd, which is typically started during the init for multiuser networked runlevels (3 and 5 in RH machines). Since we're starting it now, that would seem to imply that it wasn't running beforehand, however that is not the case. Actually, I had replaced /etc/init.d/sshd with a cluster-aware version that pointed various key files to the clustered filesystems. Here are the changes:
# Begin cluster-ssh modifications
if [ -z "$OCF_RESKEY_service_name" ]; then
#
# Normal / system-wide ssh configuration
#
RSA1_KEY=/etc/ssh/ssh_host_key
RSA_KEY=/etc/ssh/ssh_host_rsa_key
DSA_KEY=/etc/ssh/ssh_host_dsa_key
PID_FILE=/var/run/sshd.pid
else
#
# Per-service ssh configuration
#
RSA1_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_key
RSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_rsa_key
DSA_KEY=/etc/cluster/ssh/$OCF_RESKEY_service_name/ssh_host_dsa_key
PID_FILE=/var/run/sshd-$OCF_RESKEY_service_name.pid
CONFIG_FILE="/etc/cluster/ssh/$OCF_RESKEY_service_name/sshd_config"
[ -n "$CONFIG_FILE" ] && OPTIONS="$OPTIONS -f $CONFIG_FILE"
prog="$prog ($OCF_RESKEY_service_name)"
fi
[ -n "$PID_FILE" ] && OPTIONS="$OPTIONS -o PidFile=$PID_FILE"
# End cluster-ssh modifications
I got these changes from this wiki entry, and it seemed to work stably, even if the rest of the cluster didn't always.
You'll also notice that I specify all the things in the services section that normally exist in /etc/exports. That file isn't used in RHCS-clustered NFS. The equivalent of exports is generated on the fly by the cluster system. This implies that you should turn off the NFS daemon and let the cluster manager handle it.
When it comes to Samba, you're going to need to create configurations for the cluster manager to point to, since the configs aren't generated on the fly like NFS. The naming scheme is /etc/samba/smb.conf.SHARENAME, so in the case of Operations above, I used /etc/samba/smb.conf.Operations. I believe that rgmanager (resource group manager) automatically creates a template for you to edit, but be aware that it takes a particular naming scheme.
Assuming you've created cluster aware LVM volumes (you did read the howto I linked to earlier, right?), you'll undoubtedly want to create a filesystem. GFS is the most common filesystem for RHCS, and can be made using 'mkfs.gfs2', but before you start making filesystems willy-nilly, you should know a few things.
First, GFS2 is a journaled filesystem, meaning that data that will be written to disk is written to a scratch pad first (the scratch pad is called a journal), then copied from the scratch pad to the disk, thus if access to the disk is lost while writing to the filesystem, it can be recopied from the journal.
Each node that will have write access to the GFS2 volume needs to have its own scratch pad. If you've got a 3 node cluster, that means you need three journals. If you've got 3 and you're going to be adding 2 more, just make 5 and save yourself a headache. The number of journals can be altered later (using gfs2_jadd), but just do it right the first time.
For more information on creating and managing gfs2, check the Redhat docs.
I should also throw in a note about lock managers here. Computer operating systems today are inherently multitasking. Whenever one program starts to write to a file, a lock is produced which prevents (hopefully) other programs from writing to the same file. To replicate that functionality in a cluster, you use a "lock manager". The old standard was GULM, the Grand Unified Lock Manager. It was replaced by "DLM", the Distributed Lock Manager. If you're reading documentation that openly suggests GULM, you're reading very old documentation and should probably look for something newer.
Once you've got your cluster configured, you probably want to start it. Here's the order I turned things on in:
# starts the cluster manager
service cman start
# starts the clustered LVM daemon
service clvmd start
# mounts the clustered filesystems (after clvmd has been started)
mount -a
# starts the resource manager, which turns on the various services, etc
service rmanager start
I've found that running these in that order will sometimes work and sometimes they'll hang. If it hangs, it's waiting to find other nodes. To remedy that, I try to start the cluster on all nodes at the same time. Also, if you don't the post_join_delay will bite your butt and fence the other nodes.
Have no false assumptions that this will work the first time. Or the second. As you can see, I made it to my 81st configuration before I gave up, and I did a fair bit of research between versions. Make liberal use of your system logs, which will point to reasons that your various cluster daemons are failing, and try to divine the reasons.
Assuming that your cluster is up and running, you can check on the status with clustat. Move the services with clusvcadm, and manuallyfence nodes with fence_manual. Expect to play a lot, and give yourself a lot of time to play and test. Test Test Test. Once your cluster is stable, try to break it. Unplug machines, network cables, and so on, watching logs to see what happens, when, and why. Use all the documentation you can find, but keep in mind that it may be old.
The biggest source of enlightenment (especially to how screwed I was) came from the #linux-cluster channel on IRC. There are mailing lists, as well, and if you're really desperate, drop me a line and I'll try to find you help.
So that's it. A *long* time in the making, without a happy ending, but hopefully I can help someone else. Drop a comment below regaling me with stories of your great successes (or if RHCS drove you to drink, let me know that too!).
Thanks for reading!
Friday, April 10, 2009
Possible Nagios Conference in Baltimore
The LinkedIn Nagios Users Group posted a link to a survey to gauge interest in Nagios conference in Baltimore, MD timed to coincide with LISA, the misnamed Large Installation Systems Administration conference.
If you're considering going to LISA (and you should at least consider it) and you'd like to attend a Nagios Conference at the same time, take the survey.
I'd like to go, I just can't afford the price tag, and I know my work wouldn't cover it.
If you're considering going to LISA (and you should at least consider it) and you'd like to attend a Nagios Conference at the same time, take the survey.
I'd like to go, I just can't afford the price tag, and I know my work wouldn't cover it.
Thursday, April 9, 2009
How NOT to cool your server room
This is a great anonymous set of pictures from someone who was working in an old machine room and was amused and horrified by what they found:

Yes, that is a box fan zip tied to a cable ladder, hanging under a cooling duct.



Yes, that is a box fan zip tied to a cable ladder, hanging under a cooling duct.
Fail.
Tuesday, April 7, 2009
What to look for in virtualization?
If you're not using virtualization yet, you probably have no idea where to even start looking. You hear about platforms, you're inundated by ads and news coverage and it's everywhere, even though it's ephemeral. No one seems to be answering basic questions, everyone assumes that you've got a virtualization infrastructure or you're getting one, and they're all saying theirs is the best.
So what do you do?
Andrew Clifford has been working hard to educate people on virtualization. Near the end of April, he produced a Virtualization Primer (part 1) to help give people a handle on the subject. He followed that up a week later with Part 2. Yesterday he put together a list of the most frequently seen virtualization platforms.
These posts serve as an excellent introduction to virtualization. You don't have to be a large enterprise entity to take advantage of it, and plenty of free solutions are available for everyone, regardless of platform.
If you're curious about what else you virtualization can help with, Philip Sellers wrote a guest blog entry awhile back about how virtualization helped him patch software, and there have been a couple other posts which mentioned it, too.
If you've got a take on virtualization, or a question, post it below and I (or more likely some other reader) can probably help you out.
So what do you do?
Andrew Clifford has been working hard to educate people on virtualization. Near the end of April, he produced a Virtualization Primer (part 1) to help give people a handle on the subject. He followed that up a week later with Part 2. Yesterday he put together a list of the most frequently seen virtualization platforms.
These posts serve as an excellent introduction to virtualization. You don't have to be a large enterprise entity to take advantage of it, and plenty of free solutions are available for everyone, regardless of platform.
If you're curious about what else you virtualization can help with, Philip Sellers wrote a guest blog entry awhile back about how virtualization helped him patch software, and there have been a couple other posts which mentioned it, too.
If you've got a take on virtualization, or a question, post it below and I (or more likely some other reader) can probably help you out.
Monday, April 6, 2009
Congrats to the winners!
On Friday, I used random.org to select 12 rubber ducky winners, to whom I've sent emails congratulating them. I've received 9 replies so far, and the first floatilla of ducks will be going out in the mail today.
I want to thank all of you who took the survey and who offered advice. I've implemented a couple of suggestions already, and I plan on continuing to work to improve the blog.
The most suggested improvement was to get away from blogger, by far. I have been considering that for a while, to the point that I bought my own domain, http://standalone-sysadmin.com. I have not decided the best way of proceeding that will allow a balance of keeping my existing subscribers and allowing growth in the future. I'm definitely open to suggestions.
Another widely requested suggestion is more frequent blog entries (although I did get a couple of responses from people who have trouble keeping up now. When I move to my new site, maybe I'll create some sort of digest option by week so that people can easily read offline). I'll be attempting to schedule more blog entries ahead of time. If I write them during my free time, it will all work out. At least, it will if I find some free time ;-)
Thank you all again!
I want to thank all of you who took the survey and who offered advice. I've implemented a couple of suggestions already, and I plan on continuing to work to improve the blog.
The most suggested improvement was to get away from blogger, by far. I have been considering that for a while, to the point that I bought my own domain, http://standalone-sysadmin.com. I have not decided the best way of proceeding that will allow a balance of keeping my existing subscribers and allowing growth in the future. I'm definitely open to suggestions.
Another widely requested suggestion is more frequent blog entries (although I did get a couple of responses from people who have trouble keeping up now. When I move to my new site, maybe I'll create some sort of digest option by week so that people can easily read offline). I'll be attempting to schedule more blog entries ahead of time. If I write them during my free time, it will all work out. At least, it will if I find some free time ;-)
Thank you all again!
Friday, April 3, 2009
Last chance for a duck!
The response to the rubber ducky giveaway has been great. I've gotten well over 50 entries, and a lot of people have entered just to answer the survey. Thank you everyone!
Today is your last chance. I'm closing the survey tonight at 5pm Eastern, so enter while the entering is good!
Today is your last chance. I'm closing the survey tonight at 5pm Eastern, so enter while the entering is good!
Subscribe to:
Comments (Atom)


