First off, lets discuss life without LVM. Back in the bad old days, you had a hard drive. This hard drive could have partitions. You could install file systems on these partitions, and then use those filesystems. Uphill both ways. It looked a lot like this:
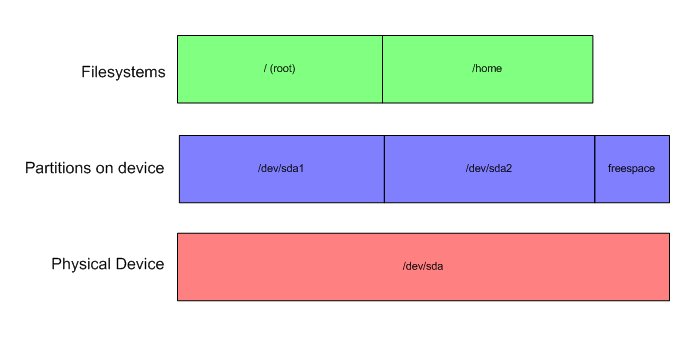
You've got the actual drive, in this case sda. On that drive are two partitions, sda1 and sda2. There is also some unused free space. Each of the partitions has a filesystem on it, which is mounted. The actual filesystem type is arbitrary. You could call it ext3, reiserfs, or what have you. The important thing to note is that there is a direct one-to-one corrolation between disk partitions and possible file systems.
Lets add some logical volume management that recreates the exact same structure:
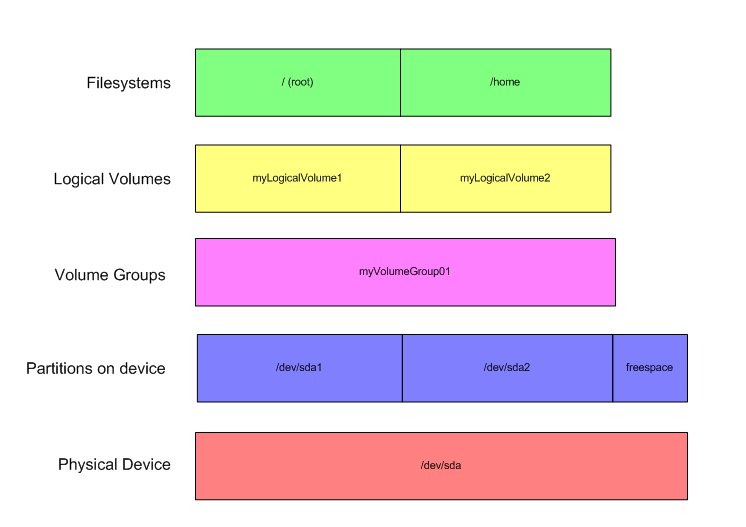
Now, you see the same partitions, however there is a layer above the partitions called a "Volume Group", literally a group of volumes, in this case disk partitions. It might be acceptible to think of this as a sort of virtual disk that you can partition up. Since we're matching our previous configuration exactly, you don't get to see the strengths of the system yet. You might notice that above the volume group, we have created logical volumes, which might be thought of as virtual partitions, and it is upon these that we build our file systems.
Lets see what happens when we add more than one physical volume:
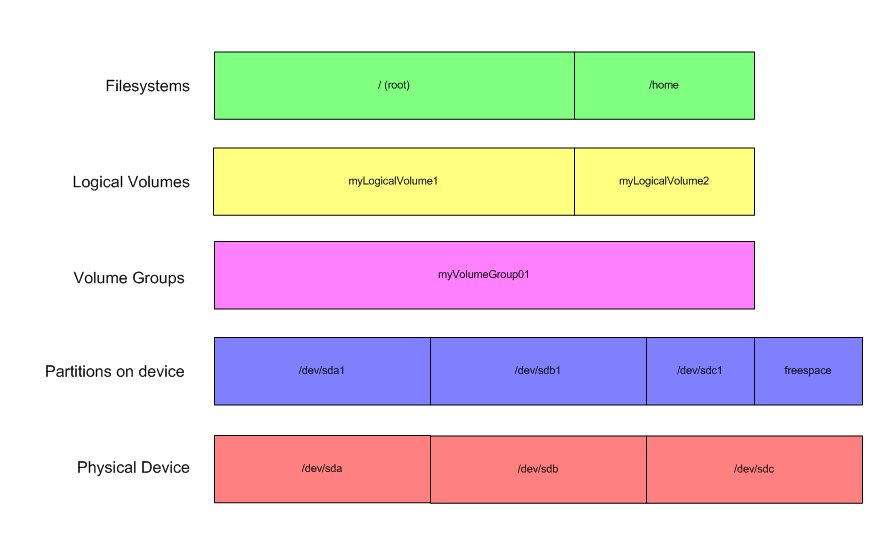
Here we have three physical disks, sda, sdb, and sdc. Each of the first two disks has one partition taking up the entire spae. The last, sdc, has one partition taking up half of the disk, with half remaining unpartitioned free space.
We can see the volume group above that which includes all of the currently available volumes. Here lies one of the biggest selling points. You can build a logical partition as big as the sum of your disks. In many ways, this is similar to how RAID level 0 works, except there's no striping at all. Data is written for the most part linearly. If you need redundancy or the performance increases that RAID provides, make sure to put your logical volumes on top of the RAID arrays. RAID slices work exactly like physical disks here.
Now, we have this volume group which takes up 2 and 1/2 disks. It has been carved into two logical volumes, the first of which is larger than any one of the disks. The logical volumes don't care how big the actual physical disks are, since all they see is that they're carved out of myVolumeGroup01. This layer of abstraction is important, as we shall see.
What happens if we decide that we need the unused space, because we've added more users?
Normally we'd be in for some grief if we used the one to one mapping, but with logical volumes, here's what we can do:

Here we've taken the previously free space on /dev/sdc and created /dev/sdc2. Then we added that to the list of volumes that comprise myVolumeGroup01. Once that was done, we were free to expand either of the logical volumes as necessary. Since we added users, we grew myLogicalVolume2. At that point, as long as the filesystem /home supported it, we were free to grow it to fill the extra space. All because we abstracted our storage from the physical disks that it lives on.
Alright, that covers the basic why of Logical Volume Management. Since I'm sure you're itching to learn more about how to prepare and build your own systems, here are some excellent resources to get you started:
http://www.pma.caltech.edu/~laurence/Linux/lvm.html
http://www.freeos.com/articles/3921/
http://www.linuxdevcenter.com/pub/a/linux/2006/04/27/managing-disk-space-with-lvm.html
As always, if you have any questions about the topic, please comment on the story, and I'll try to help you out or point you in the right direction




